5.3 Entradas/Salidas
§1 Introducción
Al tratar de Entradas/Salidas en C++, es primordial señalar que estas operaciones no están contempladas como tales en el lenguaje. Dicho en otras palabras: en C++ no existen elementos léxicos que permitan soportar este tipo de operaciones. Significa también que las E/S, que son imprescindibles en cualquier programa, deben realizarse mediante utilidades "de librería", de las que el Estándar C++ proporciona un buen surtido.
Para entender el doble modelo utilizado en C++ para las E/S,
es conveniente hacer una pequeña reseña histórica. Como se ha dicho,
C++ deriva de C; en principio fue un mero preprocesador que pasaba el
código C++ a C, en que era compilado; de forma que usaba las librerías C
(que heredó). Estas librerías se denominan "Clásicas", y en
el caso concreto de las de E/S, se conocen también como librerías stdio
o cstdio, en referencia al fichero de cabecera (clásico o moderno) en
que están definidas (<stdio> o <cstdio>).
Posteriormente, se decidió reescribir y reestructurar las librerías de E/S C
(hacer las más ++) para aprovechar las mejoras y posibilidades que ofrecía
el lenguaje respecto al anterior [8]. Sin embargo, se
decidió mantener el antiguo esquema de uso por compatibilidad, con el
resultado de que en el C++ actual, conviven dos esquemas de manejo de E/S que
pueden ser utilizados indistintamente (no es raro encontrar aplicaciones que
utilizan ambos). Las nuevas librerías se fueron agrupando
en un conjunto de cabeceras distintas de las anteriores compartiendo un
subespacio de nombres específico (std ![]() 4.1.11c2). Actualmente, junto con otros
añadidos posteriores (las plantillas), conforman el binomio STL/IOStream
Libray, que albergan las formas ++ de hacer las cosas [9].
4.1.11c2). Actualmente, junto con otros
añadidos posteriores (las plantillas), conforman el binomio STL/IOStream
Libray, que albergan las formas ++ de hacer las cosas [9].
Nota: en C y C++, las E/S se conceptualizan como "Flujos" (ver a continuación) cuya materialización concreta en el programa es un objeto; una estructura o una instancia de clase (según el caso). Estos objetos se denominan Streams (a secas) si se refieren a los de la librería clásica e IOStreams si se refieren a la librería C++.
§2 Conceptos básicos
Antes de entrar en detalles daremos un repaso a algunos conceptos básicos para entender cual es la filosofía de funcionamiento que subyace en las rutinas C++ de E/S. Advirtiendo de paso que, el tratamiento un tanto especial dado a estas operaciones, debe su idiosincrasia a su antecesor C, quien lo toma a su vez del Unix, sistema en el que anduvo sus primeros pasos.
§2.1 Archivo
Se supone que las entradas y salidas (E/S) de información se producen hacia/desde archivos o ficheros ("files"). En C/C++ este es un concepto muy genérico, dado que un archivo puede ser un fichero en disco; una impresora; una cinta magnética; una colección de fichas perforadas; una consola, o un teclado. Es decir, desde el punto de vista del programa, el concepto de archivo puede entenderse como “dispositivo” externo hacia/desde el que puede fluir información. Es evidente que no todos los archivos soportan las mismas operaciones. Por ejemplo, una cinta magnética soporta acceso secuencial, mientras que un disco magnético soporta E/S aleatoria [1]. Una impresora solo soporta operaciones de salida (desde el programa que imprime) mientras que un micrófono solo proporciona entradas (hacia el programa que recibe la señal).
§2.2 Flujo (stream)
Las operaciones de E/S de C y C++ se conceptualizan como corrientes de datos que entran y salen del programa hacia/desde distintos tipos de archivos (como hemos visto, dispositivos que pueden incluir teclado, consola, discos, cintas, Etc.) Aunque cada dispositivo es diferente, el programa utiliza un solo concepto de corriente de datos, denominado flujo ("stream"). Y en lo concerniente al programador, permite tratarlos de forma similar. Es decir, dentro de los posible, el sistema C++ de E/S desvincula el flujo del dispositivo concreto con el que se realiza la transferencia.
El flujo de datos es desde luego una sucesión bits que pueden representar cualquier cosa: tipos simples (predefinidos en el leguaje) como int o float; tipos abstractos (instancias de clases); flujos de caracteres ASCII o UNICODE; píxels de una imagen, o notas de una melodía.
Hay que hacer notar que la unidad de flujo C/C++ es el carácter (se leen y escriben caracteres), que pueden ser sencillos (char), anchos (wchar_t), o de cualquier otro tipo definido por el usuario, siempre que se adapte a ciertas normas. El formato y juego de caracteres utilizado puede ser cualquiera. De hecho, el formato y juego de caracteres de los datos que se transmiten por el "stream" no tienen porqué coincidir con el formato y juego de caracteres utilizados para su representación interna (los procesos de transferencia se encargan de realizar las conversiones pertinentes).
Nota: como consecuencia de esta diferencia, es frecuente referirse a la representación
interna de los datos, tal como se almacenan en el programa. Por
ejemplo, la representación ASCII de los caracteres (![]() 2.2.1a) o la representación IEEE de los números (
2.2.1a) o la representación IEEE de los números (![]() 2.2.4a), y la representación externa, que depende del dispositivo externo. Esta forma no es
la misma si el dispositivo es una pantalla que si es una tarjeta de red.
2.2.4a), y la representación externa, que depende del dispositivo externo. Esta forma no es
la misma si el dispositivo es una pantalla que si es una tarjeta de red.
Es importante entender que, desde la óptica del programa,
los flujos se suponen siempre desde/hacia el programa o pasando por él
(aunque un flujo de entrada puede ser reconducido hacia otra salida -otro
destino-). Como cabría esperar, los flujos C++ se concretan en objetos,
instancias de ciertas clases preparadas al efecto (iostreams
![]() 5.3.1).
Recordar también que, aunque parezca una contradicción, el flujo puede estar
desligado de cualquier fichero. Es la situación que se presenta cuando
se instancia un objeto-flujo que no está asociado a ningún
dispositivo. En estas condiciones se supone que el programa ha preparado
un mecanismo capaz de determinado tipo de operación de E/S. Aunque
naturalmente, mientras no esté relacionado con algún dispositivo (fichero),
no es posible la operación del mecanismo (podríamos figurarnos un jardinero
que prepara una manguera pero no la conecta a ningún sitio).
5.3.1).
Recordar también que, aunque parezca una contradicción, el flujo puede estar
desligado de cualquier fichero. Es la situación que se presenta cuando
se instancia un objeto-flujo que no está asociado a ningún
dispositivo. En estas condiciones se supone que el programa ha preparado
un mecanismo capaz de determinado tipo de operación de E/S. Aunque
naturalmente, mientras no esté relacionado con algún dispositivo (fichero),
no es posible la operación del mecanismo (podríamos figurarnos un jardinero
que prepara una manguera pero no la conecta a ningún sitio).
|
Figura 1 (del manual Borland "Standard C++ Library") |
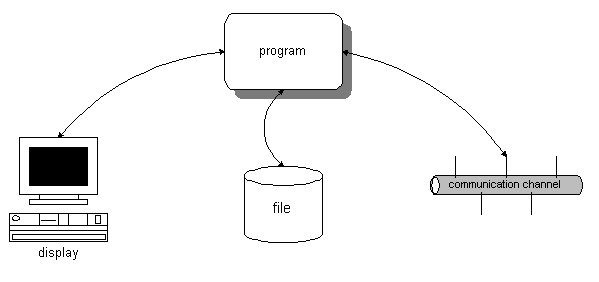
La figura 1 muestra varios de estos flujos de datos entre un programa y tres dispositivos externos. En este caso con una pantalla; un fichero de disco, y un dispositivo de comunicaciones.
El hecho de conectar (asociar) un flujo a un archivo (dispositivo) se conoce como abrir (open) el archivo. A la inversa, el hecho de desligar el flujo del archivo se conoce como cerrarlo (close).
En C, la rutina que abre un archivo devuelve un puntero ("file pointer") a una estructura de tipo FILE que contiene la información necesaria para controlar el flujo [2]. En C++ son las propiedades del objeto-flujo las que contienen dicha información.
Cuando se trata de flujos de salida, en el momento de cerrar la conexión se ha realizado toda la transferencia.
Es decir, todos los datos se han volcado (escrito) en el dispositivo receptor. Cuando el
programa termina normalmente, todos los flujos son cerrados. No así cuando aborta (se termina mediante una llamada a
abort ![]() 1.5.1).
1.5.1).
En lo concerniente al programador, las E/S pueden ser abordadas como flujos de caracteres, sin preocuparse gran cosa del dispositivo físico real al que estén conectados estos flujos. Como veremos a continuación, las utilidades de E/S encapsulan las peculiaridades de cada dispositivo físico externo.
§2.3 Redireccionamiento
Es importante señalar que la mayoría de los sistemas operativos permiten redireccionar estos flujos de unos dispositivos (ficheros) a otros. Por ejemplo, la entrada estándar de un programa puede ser redireccionada desde el teclado a un fichero de disco, de donde el programa obtendrá los datos de entrada. Así pues, por redireccionamiento se entiende la capacidad que tienen los SO de desviar el flujo que normalmente iría a un dispositivo hacia otro.
Nota: en realidad, el término redireccionamiento se suele utilizar cuando la salida de un proceso se dirige a un fichero de disco. Por ejemplo, un flujo que debería aparecer en pantalla, es redirigido a un fichero de disco para poder después modificarlo, listarlo, transmitirlo, etc. Cuando la salida de un proceso de redirige de forma que constituya la entrada de otro, se utiliza el término entubado ("piping"). A continuación mostramos dos ejemplos utilizando el shell de DOS y el de Linux [10]:
DOS/Windows:
Redireccionamiento
dir *.* > listado.txtEntubado:
edit > dir t*.txtLinux
Redireccionamiento
ls -l > listado.txtEntubado
ls -l | wc
§2.4 Modos de flujo
Se distinguen dos modos básicos de flujo: binarios y de texto. Este último se presenta en
dos modalidades: formateado y no formateado. Generalmente la forma en que se efectuará el flujo queda determinado en el
momento de abrir (open) el fichero asociado. Por ejemplo, la función de librería clásica fopen
(![]() 5.5.2), que permite abrir
un fichero, acepta una serie de argumentos, entre los que se encuentran información sobre la
dirección del flujo (lectura, escritura o ambos), así como su modo (de texto o binario).
5.5.2), que permite abrir
un fichero, acepta una serie de argumentos, entre los que se encuentran información sobre la
dirección del flujo (lectura, escritura o ambos), así como su modo (de texto o binario).
§2.4.1 Flujos de texto
Los flujos de texto están relacionados con el proceso de textos y/o el intercambio de secuencias de caracteres entre el programa y dispositivos externos (por ejemplo, comunicaciones o acceso a ficheros de disco). Las líneas de caracteres pueden terminar en ‘\n’. Se acepta que en ciertos entornos se puedan realizar determinados formateos y conversiones de código, lo que hace que pueda no haber una correspondencia exacta entre los caracteres que son escritos/leídos por el sistema y los existentes en el dispositivo externo.
-
Formateo: Es el proceso por el que una secuencia de bits representando datos internos es transformada en una secuencia de caracteres inteligible para el humano. Por ejemplo, la secuencia de 4 bytes 01000000010010010000111111010000 que representa internamente un float, es transformada en la secuencia de dígitos y signos de puntuación: 3.1415901. El formateo también incluye conversiones menores de tipo cosmético, como sustituir las ocurrencias de CR y NL en CR+LF.
-
Conversión de código: Este tipo de proceso consiste en la sustitución de uno o varios caracteres por otro. Se asocian generalmente a codecs de compresión/descompresión. Se utilizan frecuentemente en los procesos de transmisión, donde se intenta minimizar la información transmitida por el canal y en los de almacenamiento externo, en los que también se intenta minimizar la cantidad de información almacenada. Es típico el caso en que los caracteres anchos, que tienen todos el mismo número de bits y son por tanto adecuados como forma de representación interna del programa. Sin embargo, son transformados en caracteres multibyte para su almacenamiento externo o transmisión. Estos caracteres, que tienen distinto tamaño, no son muy adecuados para su proceso, pero almacenan la información de forma más densa que los caracteres anchos.
§2.4.2 Flujos binarios
Todos los flujos que no son de texto se consideran binarios. Se caracterizan porque existe una correspondencia exacta entre los caracteres que componen el flujo y los que aparecen en el archivo (dispositivo externo).
§2.5 Tipos de flujo
Aunque generalmente los flujos se refieren a intercambios de datos hacia/desde dispositivos externos de cualquier tipo, existe un caso límite en el que el intercambio no se realiza con ningún dispositivo externo, sino con memoria. Esta circunstancia hace que puedan considerarse dos tipos de flujo (en cualquiera de los modos anteriores) según el tipo de "dispositivo" con el que se realiza el intercambio:
- Flujos de fichero
- Flujos de memoria.
Los flujos de fichero se refieren a los flujos hacia/desde dispositivos externos que se ajusten al concepto C++ de "file" (no necesariamente ficheros de disco). Para evitar ambigüedades, en adelante los denominaremos por su nombre inglés: "File I/O".
Los flujos de memoria no se refieren a ningún dispositivo externo, ya que la transferencia se realiza en la propia memoria. Por esta razón las rutinas que los controlan no precisan de la capa de transporte (ver a continuación) e implican solo operaciones de formateo. Se denominan "In-memory I/O".
§3 Operaciones de flujo
Cualquier operación de E/S puede suponerse dividida en una sucesión de operaciones individuales. Si escogemos como ejemplo una salida, el orden sería el siguiente:
- Formateo / Análisis.
- Almacenamiento intermedio
- Conversión de código
- Transporte.
La primera operación es de formateo o análisis ("Parsing"), según se trate de una operación de salida de datos o de llegada (entrada). En el primer caso, el formateo supone recoger los datos de su correspondiente Lvalue y transformarlos en un conjunto de caracteres. Por ejemplo, si se va a enviar un long, sus 32 bits son divididos en 4 caracteres. El Análisis es la operación contraria. Por ejemplo, si se reciben los caracteres -1.25 y van a ser almacenados como un long, los 5 caracteres de la secuencia son transformados en una palabra de 32 bits.
Para facilitar las operaciones y mejorar su rendimiento, los flujos utilizan un área de memoria en la que se almacenan trozos que van siendo procesados sucesivamente. Evidentemente el contenido de este almacenamiento intermedio o buffer de flujo [5] son caracteres, y generalmente son leídos y escritos por grupos. Se dice que las operaciones son "Buffered". Es decir, utilizan el almacenamiento intermedio por defecto, aunque este comportamiento puede modificarse.
La fase de conversión de código
no siempre es necesaria, pero en su caso, se ocupa de transformar el esquema de
codificación utilizado internamente por el que necesita o acepta el
dispositivo externo. Por ejemplo, la representación interna de los
caracteres suele ser de ancho fijo (char, wchar_t o de cualquier
otra longitud) que es muy adecuada para manipulaciones en memoria. En
cambio, los dispositivos de almacenamiento y comunicaciones suelen utilizar codificaciones multibyte que consiguen mayor
densidad de información (![]() 2.2.1a0).
2.2.1a0).
La fase de transporte implica escribir (o leer) el flujo de caracteres en el dispositivo correspondiente.
Como veremos a continuación
![]() , las operaciones anteriores están encapsuladas en
dos capas y esta disposición se refleja en la arquitectura de la librería IOStream (algo similar a lo que supone el
modelo OSI en las comunicaciones de red). La disposición sería la siguiente:
, las operaciones anteriores están encapsuladas en
dos capas y esta disposición se refleja en la arquitectura de la librería IOStream (algo similar a lo que supone el
modelo OSI en las comunicaciones de red). La disposición sería la siguiente:
- Capa de formato. Se ocupa de las tareas de formateo y análisis anteriormente descritas.
- Capa de Transporte. Engloba todas las demás y está controlada por el objeto que representa el buffer intermedio. Además de controlar el almacenamiento propiamente dicho, se ocupa de las operaciones de conversión de código y transporte.
§4 Flujos estándar
Cuando se inicia un programa C tradicional, las rutinas de inicio crean por defecto tres flujos, conocidos genéricamente como flujos estándar (stdIO), que son inicialmente asociados a dispositivos concretos (abiertos). Sus nombres y los dispositivos a los que se asocian, son estándar y universalmente aceptados:
- Flujo estándar de entrada: stdin ("Standard input"); por defecto asociado al teclado.
- Flujo estándar de salida: stdout ("Standard output"); por defecto asociado a la pantalla.
- Flujo estándar de salida de error: stderr ("Standard error"); por defecto asociado a la pantalla.
Además de los flujos correspondientes al C estándar, las rutinas de inicio de un programa C++
(![]() 1.5) crean e inician ocho flujos adicionales, que son inicialmente
asociados (*) a los dispositivos estándar C. Es decir, a la pantalla y al teclado (al terminal utilizado para lanzar el
programa). Como resultado, un programa C++ estándar mantiene un
mínimo 11 flujos abiertos en el momento de su inicio. Los nombres y funcionalidad son los indicados en la
tabla (**).
1.5) crean e inician ocho flujos adicionales, que son inicialmente
asociados (*) a los dispositivos estándar C. Es decir, a la pantalla y al teclado (al terminal utilizado para lanzar el
programa). Como resultado, un programa C++ estándar mantiene un
mínimo 11 flujos abiertos en el momento de su inicio. Los nombres y funcionalidad son los indicados en la
tabla (**).
|
Flujos C++ |
Flujo C asociado |
|
|
Caracteres estrechos |
Caracteres anchos |
|
|
cin |
wcin |
stdin |
|
cout |
wcout |
stdout |
|
cerr |
wcerr |
stderr |
|
clog |
wclong |
stderr |
(*) Esta "asociación" debe interpretarse en el sentido de "sincronización" señalado más
adelante ![]() .
.
(**) En las aplicaciones gráficas Windows, la
"pantalla" -en el sentido de la consola DOS como tal- ha desaparecido,
siendo sustituida por las consabidas ventanas gráficas, al tiempo que los flujos (mensajes)
destinados a los dispositivos estándar de salida, stdout y stderr son
descartados. Sin embargo, es posible conseguir que una de estas aplicaciones gráficas
muestre también la correspondiente consola, lo que puede ser útil en algunos procesos
de depuración. Para ello, basta incluir el siguiente trozo de código en la
función de inicio WinMain()
AllocConsole();
freopen ("CONOUT$", "a", stderr);
freopen ("CONOUT$", "a", stdout);
Obsrve que en caso de utilizar este recurso, la ventana que
representa la consola, será cerrada junto con la ventana principal al terminal
la aplicación (lo que debe hacerse en la ventana gráfica).
El Estándar establece que estos flujos pueden ser cerrados, pero no
destruidos durante la vida del programa. La diferencia entre los flujos de error cerr y clog
(en sus dos versiones) es que clog es "Fully buffered";
almacenado en memoria intermedia hasta que el mensaje de error está completo
![]() .
Mientras que cerr es escrito en el terminal después de cada formateo. La consecuencia es que clog es más
eficiente para redireccionar la salida a un fichero de disco, mientras que cerr puede ser mantenido para E/S a
consola [6].
.
Mientras que cerr es escrito en el terminal después de cada formateo. La consecuencia es que clog es más
eficiente para redireccionar la salida a un fichero de disco, mientras que cerr puede ser mantenido para E/S a
consola [6].
La forma canónica de que un programa C/C++ muestre un texto, consiste en insertar una cadena de caracteres en el flujo cout. Pero observe que en una sentencia como
std::cout << "Hola mundo\n" << std::endl;
el término std::cout es en realidad el identificador cualificado de un objeto
(![]() 4.1.11c); que cout es el flujo estándar de salida, y que
este objeto es creado automáticamente cuando se utiliza #include <iostream>.
4.1.11c); que cout es el flujo estándar de salida, y que
este objeto es creado automáticamente cuando se utiliza #include <iostream>.
El operador << es una versión sobrecargada de un operador global que toma un argumento (en este caso la cadena de caracteres "Hola mundo\n") y la pasa al objeto cout. En realidad la primera parte de esta expresión es otra forma sintáctica de la invocación de un método:
std::cout.operator<<("Hola mundo\n");
El término std::endl es lo que se denomina un manipulador
(![]() 5.3.3c1); inserta un carácter NL en el flujo y fuerza el vaciado del
buffer intermedio del objeto cout.
5.3.3c1); inserta un carácter NL en el flujo y fuerza el vaciado del
buffer intermedio del objeto cout.
§4.1 Sincronización
Un aspecto de cierta importancia para entender algunas peculiaridades Librería Estándar, es saber que en un programa C++ es perfectamente lícito, y frecuente, simultanear la utilización de ambos tipos de flujos. Los clásicos de <cstdio> y los modernos de <iostream>. La razón es que los flujos correspondientes (clásicos y modernos) están sincronizados (por defecto) mediante un mecanismo que les permite compartir el mismo buffer interno [4]. A este respecto el Estándar establece: "La cabecer <iostream> declara objetos que asocian objetos con los flujos estándar C proporcionados por las funciones de la cabecera <cstdio>... Los objetos son construidos, y la asociación establecida, antes o durante la primera vez que se construye un objeto de la clase basic_ios, y en cualquier caso, antes que el cuerpo de la función main comience su ejecución".
Sin embargo, una vez iniciada la aplicación este sincronismo puede ser anulado o restablecido a voluntad mediante el método:
std::ios_base::sync_with_stdio(false);
...
std::ios_base::sync_with_stdio(); // el valor por defecto es true
La razón para se desee esta desconexión, puede ser la utilización de los flujos cin o cout en operaciones en las que se requiera la máxima velocidad de ejecución, ya que este desacople permite odviar la penalización asociada a las tareas de sincronización de las E/S.
§5 Arquitectura de las rutinas C++ de E/S
"The most innovative aspect of the C++ I/O library is that data formatting has been decoupled from character manipulation; understanding that decoupling is crucial for anything but basic use of the library". Matthew H. Austern en "The Standard Librarian: Streambufs and Streambuf Iterators". Dr. Dobb's Journal.
Como hemos adelantado, las rutinas C++ que sirven operaciones de flujo entre el
programa y un dispositivo externo, están organizadas en una
estructura de dos capas, según se muestra en la figura 2: capa de formato y capa de
transporte, e incluyen un almacenamiento temporal intermedio
denominado buffer de flujo, streambuf ("Stream buffer").
La capa de formato está representada por el objeto iostream y se encarga del formateo de datos y análisis. La capa de transporte se encarga de las conversiones de código y del transporte; está representada por el objeto streambuf.
Es importante tener clara la distinción entre los roles
asignados a una y otra capa, que son relativamente independientes. Por
ejemplo, la conexión con un nuevo dispositivo (como un "socket"),
requiere solamente la construcción de un nuevo tipo streambuf
que gestione la conexión física. A continuación solo es necesario construir un objeto iostream que esté
conectado a dicho buffer. La capa de formato dispone de las herramientas
necesarias para esta "conexión" (![]() 5.3.2b).
5.3.2b).
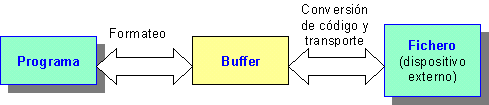
|
Figura 2 |
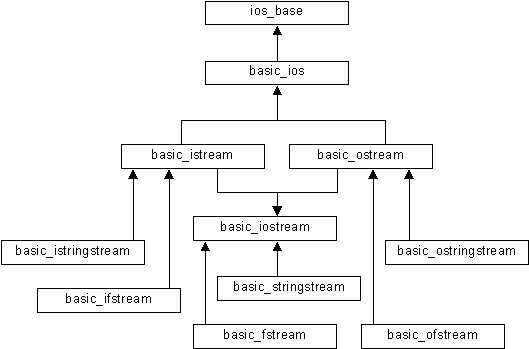
|
Figura 2a Jerarquía de clases de flujo (capa de formato). |
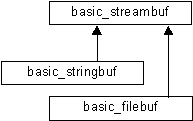
|
Figura 2b Jerarquía de clases de buffer de flujo (capa de transporte) |
§5.1 La capa de formato
(el objeto iostream) trata los datos como entidades de alto nivel, y es responsable del formateo de los que entran y salen del buffer, así como
de la supervisión global del flujo. Realiza entre otras la siguientes operaciones:
- Representación de números de coma flotante.
- Representación hexadecimal (
 2.2.4b),
octal (
2.2.4b) o decimal de los enteros.
2.2.4b),
octal (
2.2.4b) o decimal de los enteros. - Supresión de espacios en blancos del flujo de entrada
- Ajuste de ancho en campos de salida.
- Adaptación de los formatos numéricos a las convenciones locales.
La funcionalidad de esta capa está encapsulada en una jerarquía de clases denominadas clases de flujo
("Stream classes") que se muestra en la figura 2a, cuyos detalles se
comentan más adelante (![]() 5.3.2).
5.3.2).
§5.2 La capa de transporte
trata los datos a nivel físico; como mera sucesión de octetos, y es
responsable de los detalles del transporte: producir los caracteres que serán entregados al dispositivo de
salida, o recibir los caracteres entregados por el dispositivo de entrada.
Esta capa, representada por el objeto streambuf, encapsula las particularidades de los dispositivos externos, de forma que el programador no debe tratar directamente con ellos. Entre otras realiza las siguientes funciones:
- Escritura por bloques en ficheros mediante llamadas al
Sistema (recordemos que el manejo de ficheros es gestionado
directamente por el Sistema Operativo
0.2).
- Conversión de código a/desde una codificación multibyte
( 2.2.1a0).
Como se muestra en la figura 2b, la funcionalidad de la capa de transporte se encapsula en una
jerarquía de clases denominadas clases de buffer de flujo
("Stream buffer classes") que derivan de la superclase basic_streambuf
cuyos detalles se comentan más adelante (![]() 5.3.2).
5.3.2).
Al objeto de que el lector pueda avanzar una idea del tipo de código
involucrado en estos mecanismos, incluimos a
continuación unas sentencias que corresponden al proceso de
enviar una petición a un servidor remoto sobre una
conexión TCP/IP; leer su respuesta y mostrarla en el
dispositivo estándar de salida.
char* path = "/textos/some.txt";
char* hostName = "zator.com";
std::stringbuf requestBuf;
// L.3
std::ostream requestStream (&requestBuf);
// L.4
requestStream << "GET " << path << " HTTP/1.0\r\n";
// L.5
requestStream << "Host: " << hostName << "\r\n";
requestStream << "Accept: */*\r\n";
requestStream << "Connection: close\r\n\r\n";
BA::async_write (socket, resquestBuf);
// L.9
std::stringbuf responseBuf;
// L.10
std::istream responseStream (&responseBuf);
// L.11
BA::async_read (socket, responseBuf);
// L.12
std::string response;
// L.13
response_stream >> response;
// L.14
std::cout << "BEGIN message\n" << response << "\nEND message\n";
std::cout << std::endl; // L.16
Comentario:
En L.3 instanciamos un objeto de la clase stringbuf, que se encargará de manejar la conexión física con el fichero remoto. En realidad, stringbuf es un typedef de basic_stringbuf<char>, una plantilla para instanciar objetos que representan la capa de transporte (a su vez, basic_stringbuf<> es una clase derivada de streambuf).
En L.4 instanciamos un objeto de la clase basic_ostream para flujos de
salida de caracteres (ostream es un typedef de basic_ostream<char>).
Este objeto representa la capa de formato y su constructor exige la dirección de un objeto de
tipo streambuf ( 5.3.2f),
de forma que el nuevo objeto quede "conectado" con un sistema de
transporte concreto.
Las sentencias L.5 a L.8 sirven para incluir en el objeto anterior la secuencia de caracteres que será enviada al servidor. En realidad, una petición HTTP a un servidor Web (observe que la petición incluye la orden de que el servidor cierre la conexión después de enviar su respuesta).
En L.9 utilizamos una supuesta función de librería async_write [11] que permite escribir el flujo anterior en un fichero representado por su primer argumento. En este caso, socket es un objeto que representa un dispositivo externo -un servidor remoto que acepta operaciones de E/S sobre una conexión TCP/IP-. socket juega aquí un papel similar al de la estructura FILE en las operación de E/S de la librería tradicional C. También, como en el caso de C, el fichero debe ser abierto antes de leer o escribir en él, aunque naturalmente, los datos a proporcionar son distintos que para abrir un fichero de disco. En este caso, la "dirección" del fichero está representada por su URL y el "modo" de operación por el tipo de protocolo a utilizar (ipv8 o ipv16) y el número de puerto (esta operación de "apertura" no está representada en el código del ejemplo).
Las líneas L.10 y L.11 son análogas a L.3/L.4, pero ahora instanciamos un objeto de la clase basic_istream que permite manejar flujos de entrada.
La sentencia de lectura L.12 es análoga a L.9, con la diferencia de que lee fichero externo representado por socket y coloca el resultado en el buffer de entrada.
La sentencia L.13 crea una cadena de caracteres; el contenido del buffer de entrada es copiado en dicho almacenamiento mediante la sentencia L.14.
La sentencia L.15, copia el contenido de la cadena, junto con un pequeño preámbulo y un epílogo ("postamble"), en el dispositivo estándar de salida -que suponemos es la consola-.
Finalmente, la sentencia L.16 es utilizada para forzar el vaciado de buffer, de forma que la totalidad del mensaje sea escrito en el dispositivo correspondiente.
§5.3 La finalidad del buffer de flujo
es reducir el número de accesos al dispositivo externo. Su funcionamiento es el siguiente:
- En las operaciones de salida, la capa de formateo envía secuencias de caracteres almacenándolas en el buffer
de flujo. Generalmente el envío al dispositivo externo se realiza solo cuando esta memoria intermedia está llena o cuando se
indica explícitamente (Vaciado de buffers en C++
 5.3.4).
5.3.4).
- En las operaciones de entrada, la capa de transporte lee una secuencia de bytes del dispositivo externo y los deposita en el buffer. A su vez la capa de formateo lee los caracteres del buffer. Cuando el buffer se ha vaciado la capa de transporte es encargada de llenarlo de nuevo.
Nota: el comportamiento normal es escribir en el dispositivo externo solo cuando el buffer está lleno, y se denomina de buffer completo ("Fully buffered"). Pero algunos flujos no son almacenados en memoria intermedia, de forma que, a costa de un menor rendimiento, los datos son escritos en el dispositivo externo sin ningún retraso. Por ejemplo, el caso de los mensajes de error.
En algunos casos el buffer de flujo puede recibir denominaciones especiales. Por ejemplo buffer de fichero
("file buffer") cuando la operación se refiere a una E/S de fichero, y buffer de cadena ("string
buffer"), cuando se refiere a una E/S de memoria
![]() .
Nosotros lo denominaremos también buffer intermedio o más sencillamente streambuf (en
realidad un typedef de std::basic_streambuff<char>) si nos
referimos a un buffer genérico; filebuf, si nos referimos a uno de fichero y stringbuf
en caso de buffer de memoria.
.
Nosotros lo denominaremos también buffer intermedio o más sencillamente streambuf (en
realidad un typedef de std::basic_streambuff<char>) si nos
referimos a un buffer genérico; filebuf, si nos referimos a uno de fichero y stringbuf
en caso de buffer de memoria.
|
Figura 3 |
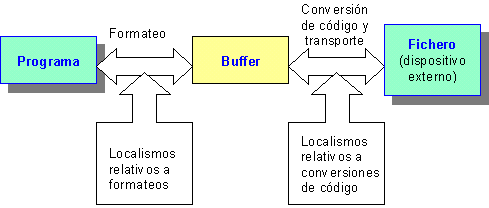
§6 Localismos
Tanto la capa de formato como la de transporte utilizan el mecanismo C++ de internacionalización
(![]() 5.2), de forma que la capa
de formato delega en los localismos numéricos para el manejo de estos formatos,
y la de transporte utiliza los localismos de conversión de códigos para las
conversiones de caracteres entre el dispositivo externo y el buffer de
E/S. La figura 3 muestra como son utilizados los localismos en los flujos de E/S.
5.2), de forma que la capa
de formato delega en los localismos numéricos para el manejo de estos formatos,
y la de transporte utiliza los localismos de conversión de códigos para las
conversiones de caracteres entre el dispositivo externo y el buffer de
E/S. La figura 3 muestra como son utilizados los localismos en los flujos de E/S.
El mecanismo se concreta en que las clases (iostreams), que
representan los flujos de E/S (![]() 5.3.1), disponen de un objeto locale
asociado; sus facetas numéricas ("numeric facets") son utilizadas para
las operaciones de análisis ("Parsing") y formateo del flujo [7].
Por defecto se utilizan las directrices del locale global
(
5.3.1), disponen de un objeto locale
asociado; sus facetas numéricas ("numeric facets") son utilizadas para
las operaciones de análisis ("Parsing") y formateo del flujo [7].
Por defecto se utilizan las directrices del locale global
(![]() 5.2) pero pueden indicarse
otras. A su vez, el objeto auxiliar que representa al buffer de flujo,
dispone también de un objeto locale asociado (generalmente es una
copia del anterior). Las operaciones de E/S utilizan la faceta de conversión de código de este locale.
5.2) pero pueden indicarse
otras. A su vez, el objeto auxiliar que representa al buffer de flujo,
dispone también de un objeto locale asociado (generalmente es una
copia del anterior). Las operaciones de E/S utilizan la faceta de conversión de código de este locale.
Nota: el hecho de asociar un locale a un iostream se denomina imbuir. Esto puede hacerse de dos formas: en el momento de creación del objeto iostream, o mediante un método específico imbue() de estas clases. La sentencia puede tener el siguiente aspecto:
cout.imbue(locale::locale("english-uk"));
También se dispone de un método específico getloc() para averiguar que locale está imbuido en un iostream determinado (todo iostream tiene un locale asociado).
§7 Bibliografía/Webografía
Es uno de esos casos en que no tengo duda sobre el consejo que podría dar al respecto. La obra de
Angelika Langer y Klaus Dreft explica en detalle y de forma muy didáctica, los entresijos de sistema C++ de E/S;
el de localismos y la relación entre ambos ![]() [Langer-Kreft-2000].
[Langer-Kreft-2000].
[1] Si el archivo dispone de esta capacidad de acceso aleatorio se dice que soporta petición de posición.
[2] Esta estructura FILE está definida en la cabecera
<stdio.h>. Ver descripción y ejemplo (![]() 4.5.5c)
4.5.5c)
[3] Los flujos estándar C++ son iniciados de forma que pueden ser utilizados en constructores y
destructores de objetos estáticos (![]() 4.1.8c).
4.1.8c).
[4] En las primitivas versiones AT&T de C++, este sincronismo no existía por defecto. Pero, a pesar que la referida sincronización conlleva una cierta penalización en el rendimiento global de las operaciones de E/S, la última versión del Estándar establece que estén sincronizadas.
[5] En lo que sigue utilizaremos la versión inglesa de la palabra ("buffer"), o su versión españolizada (bufer), por ser más corta que su equivalente en español "almacenamiento intermedio" o "memoria tampón".
[6] Las interrupciones de la escritura de cerr en el terminal entre cada formateo, permite sincronizar las E/S de este.
[7] Según una propuesta de Chuk Allison al Comité de Estandarización en 1993.
[8] Los primeros trabajos al respecto datan de 1986 y se deben a Jerry Schwarz, a la sazón en los laboratorios AT&T.
[9] Para que el lector tenga una idea de magnitudes e importancias relativas, del total del Estándar actual (ISO/IEC 14882), un tercio está dedicado a la STL; otro tercio a IOStream y Locales. El tercio restante cubre todo lo demás, incluyendo la especificación del lenguaje propiamente dicho.
[10] Además de las capacidades de redireccionamiento y entubado, Unix y Linux disponen de una amplísima panoplia de utilidades, que permiten realizar casi cualquier manipulación imaginable sobre los flujos, sin necesidad de programación adicional.
[11] Tal función no existe aún en la Librería Estándar C++, pero será incluída -quizás con otro nombre- junto con otras similares en la próxima revisión del estándar -provisionalmente conocido como C++09/C++0x- cuya publicación a la fecha -Diciembre 2010- parece inminente. La nueva revisión incluirá librerías para E/S de red (comunicaciones TCP/IP) como las señaladas en las líneas 9 y 12. Por el momento, funciones muy parecidas pueden encontrarse en librerías externas. Por ejemplo, Boost.asio, que parecen ser el modelo finalmente adoptado para el estándar. Esta circunstancia la hemos señalado suponiendo que están en un espacio de nombres BA distinto de std.