1.4 Proceso de creación de un programa
Regla de oro de la programación: !! Nunca está terminado del todo ¡¡
§1 Sinopsis
Programming is the art of expressing solutions to problems so that a computer can execute those solutions. Bjarne Stroustrup: "Programming: Principles and Practice Using C++".
Escribir un programa es establecer el comportamiento de una máquina mediante una serie de algoritmos
que definirán su funcionamiento![]() .
En el estado actual de la ciencia, este algoritmo se plasma por escrito utilizando un lenguaje
artificial comprensible por el humano-programador.
Generalmente estas instrucciones, que aquí se denominan código
fuente, vienen acompañadas de algunos datos en forma de texto o imágenes,
contenidas en uno o varios ficheros denominados ficheros de recursos ("resources").
Sin embargo, las instrucciones y recursos solo pueden ser utilizadas por la máquina después de un
proceso de traducción que es realizado por la propia máquina (puede ser
distinta de la que ejecuta el programa). El proceso exige que el
código fuente sea transformado en una nueva secuencia de instrucciones según
un nuevo sistema de codificación (el lenguaje máquina), y que los
recursos adopten una disposición particular. Este conjunto de
instrucciones y datos, que constituyen el denominado ejecutable,
corresponden a acciones concretas y datos, que pueden ser entendidas, ejecutadas
y utilizados por la máquina.
.
En el estado actual de la ciencia, este algoritmo se plasma por escrito utilizando un lenguaje
artificial comprensible por el humano-programador.
Generalmente estas instrucciones, que aquí se denominan código
fuente, vienen acompañadas de algunos datos en forma de texto o imágenes,
contenidas en uno o varios ficheros denominados ficheros de recursos ("resources").
Sin embargo, las instrucciones y recursos solo pueden ser utilizadas por la máquina después de un
proceso de traducción que es realizado por la propia máquina (puede ser
distinta de la que ejecuta el programa). El proceso exige que el
código fuente sea transformado en una nueva secuencia de instrucciones según
un nuevo sistema de codificación (el lenguaje máquina), y que los
recursos adopten una disposición particular. Este conjunto de
instrucciones y datos, que constituyen el denominado ejecutable,
corresponden a acciones concretas y datos, que pueden ser entendidas, ejecutadas
y utilizados por la máquina.
![]() En general este comportamiento pretende modelar o mimetizar el comportamiento
de una entidad del mundo real, o de una abstracción que hemos imaginado; y es de tipo genérico. Se pretende que la
máquina se comporte como una función que acepta un conjunto de condiciones
de entrada y devuelve como salida un comportamiento concreto y predecible para
cada combinación de las condiciones de entrada.
En general este comportamiento pretende modelar o mimetizar el comportamiento
de una entidad del mundo real, o de una abstracción que hemos imaginado; y es de tipo genérico. Se pretende que la
máquina se comporte como una función que acepta un conjunto de condiciones
de entrada y devuelve como salida un comportamiento concreto y predecible para
cada combinación de las condiciones de entrada.
§2 Presentación del problema
Hay bastante literatura sobre programación en general; a los académicos les
gusta hablar de "Teoría de la Programación", y
mucha gente se ha dedicado a especular sobre el tema. Incluso hay modas al respecto [4].
Es posible confeccionar una lista de las características que "debe"
y "no debe" tener un buen programa (incluyendo la del Jefe, que solo
tiene dos puntos: "Que esté para ayer; que salga barato"). El
propio Stroustrup (![]() TC++PL)
compara las condiciones para escribir un buen programa con las de escribir
buena prosa. Según él, existen dos respuestas: "Saber que se quiere
decir" y "Práctica. Imitar buenos escritores". Más
adelante nos recuerda que aprender a manejar bien un lenguaje puede constar
tanto tiempo y esfuerzo como aprender a expresarse en un lenguaje natural o tocar un instrumento.
TC++PL)
compara las condiciones para escribir un buen programa con las de escribir
buena prosa. Según él, existen dos respuestas: "Saber que se quiere
decir" y "Práctica. Imitar buenos escritores". Más
adelante nos recuerda que aprender a manejar bien un lenguaje puede constar
tanto tiempo y esfuerzo como aprender a expresarse en un lenguaje natural o tocar un instrumento.
Por supuesto sería un atrevimiento por mi parte contradecir tan docta opinión,
pero puestos a filosofar me gustaría puntualizar que el verdadero problema está en el segundo punto de la segunda respuesta;
la primera, aunque ciertamente importante, me parece la verdad de Perogrullo
![]() . Siempre
me ha parecido que programar (programar bien) tiene mucho de arte. Me parece que
debe ocurrir como con la música; seguramente muchos pueden decir que debe
tener una buena ejecución de violín, pero imitar a Paganini debe ser harina
de otro costal. Seguramente los profesores de armonía saben que debe
tener y no tener una buena sinfonía, pero otra cosa debe ser imitar a Mozart.
. Siempre
me ha parecido que programar (programar bien) tiene mucho de arte. Me parece que
debe ocurrir como con la música; seguramente muchos pueden decir que debe
tener una buena ejecución de violín, pero imitar a Paganini debe ser harina
de otro costal. Seguramente los profesores de armonía saben que debe
tener y no tener una buena sinfonía, pero otra cosa debe ser imitar a Mozart.
Bajando a la tierra; tampoco se trata aquí de hacer "Paganinis de la programación C++" (ya me gustaría para mí); el mensaje que quisiera transmitir es doble: El contenido en un viejo Refrán Español: "La Universidad no presta lo que la naturaleza no da". Como suena un poco duro, añadiré un consuelo para los que somos menos dotados; un proverbio que leí hace tiempo, en línea con la respuesta de Stroustrup: "Por el dinero del trabajo los Dioses lo venden todo".
A continuación se comentan brevemente los pasos imprescindibles en la creación de un programa C++. Vaya por delante, que las anotaciones de los puntos §3, §4 y §5 son opinión del que suscribe basados en la propia experiencia, por tanto totalmente subjetivos y opinables.
§3 Comprender el problema.
"Custom development is that murky world where a customer tells you what to build, and you say, "are
you sure?" and they say yes, and you make an absolutely beautiful spec, and say, "is this what you want?" and they say yes,
and you make them sign the spec in indelible ink, nay, blood, and they do, and then you build that thing they signed off on,
promptly, precisely and exactly, and they see it and they are horrified and shocked, and you spend the rest of the week
reading up on whether your E&O insurance is going to cover the legal fees for the lawsuit you've gotten yourself into or
merely the settlement cost. Or, if you're really lucky, the customer will smile wanly and put your code in a drawer and never
use it again and never call you back". Joel on Software "Set Your Priorities"
![]() www.joelonsoftware.com
www.joelonsoftware.com
"As more became known about what people wanted to do with computer, it became clear that there would always be increasingly more complex problems to solve. A part of that realization is the realization that our ability to accurately describe the problem determines the ability for the problem to be solved. Most people are incapable of clearly and precisely articulating -- to the level necessary -- the problems that they're trying to solve. This is a problem that is getting larger and not smaller". Robert Bogue (Jupitermedia Corp) en "Breaking Down Software Development Roles".
"Often, a problem is only fully understood through the process of programming a solution for it". Bjarne Stroustrup: "Programming: Principles and Practice Using C++".
Esta es la típica obviedad que a veces se pasa por alto. Hemos dicho que escribir un programa es
establecer el comportamiento de una máquina; parece lo más natural del mundo enterarse primero de cual
es ese comportamiento. Tener una imagen mental lo más clara posible de
las características de lo que pretendemos modelar. Esta cuestión es lo que
los teóricos denominan el "espacio" del problema, "'What' domain" en la literatura inglesa.
A esta fase se la suele denominar análisis, y mi consejo particular es que después de una primera toma de contacto, el segundo paso sea definir de la forma más detallada posible el principio y el final del problema. Es decir: cual es la información de partida (incluyendo su formato y en que soporte se recibe) y cual es la información final y en que soporte se proporcionará; no es lo mismo mostrar una imagen que componer una factura o disparar un proceso si un sensor analógico-digital nos suministra una determinada señal (por citar algún ejemplo).
Normalmente en ambas cuestiones tiene mucho que decir el cliente [2], es lo que se llama especificación; el resto (lo que hay entre los datos de entrada y la salida), debe rellenarlo el programador. Generalmente si se tienen bien definidos ambos extremos, se tiene resuelta la mitad del problema; cuando se tengan diseñados los ficheros se tendrán dos terceras partes -ver a continuación-. Este sistema tiene además la ventaja de poner inmediatamente de manifiesto las indefiniciones de partida; a veces los clientes no saben exactamente qué desean y hay que ayudarles a centrar el problema.
Dentro de esta fase tiene especialísima importancia el tema de los límites; esto se refiere al orden de magnitudes que se manejarán. ¿De que rango serán las magnitudes numéricas? ¿Podrán adoptar valores negativos? ¿Hay información alfanumérica? ¿Como son de largas estas cadenas?. Especialmente si el programa implica diseño de archivos (como es casi seguro), ¿Cual podrá llegar a ser su tamaño dentro de la vida del programa?. Si se manejan ficheros u objetos binarios, ¿Como son de grandes? ¿Que concepto tiene el cliente de los que sería "rápido" o "lento"? (¿milisegundos, minutos, horas?). En esta fase sea especialmente precavido y no se crea a pié juntillas todo lo que le digan (intente hacer de abogado del diablo).
Como postre, diseñe las líneas maestras de una estrategia
de recuperación de errores de ejecución, incluyendo que hará con los no
recuperables (errores fatales). Piense por ejemplo que si algún día lo
llaman para ver "que ha pasado", quizás le interese disponer de un
volcado de texto ASCII en el disco con una descripción del estatus del
programa como parte de las funciones de salida (![]() 1.5). Hoy día, cuando se empieza a
hablar de frigoríficos que avisarán de que faltan provisiones o de lavadoras
que avisarán al técnico si se estropean, no estaría de más que sus
programas estuviesen a la altura de las circunstancias.
1.5). Hoy día, cuando se empieza a
hablar de frigoríficos que avisarán de que faltan provisiones o de lavadoras
que avisarán al técnico si se estropean, no estaría de más que sus
programas estuviesen a la altura de las circunstancias.
![]()
§4 Diseñar los ficheros y módulos
Si el programa debe utilizar ficheros que no vengan impuestos (ya existentes), y suponiendo que todo lo anterior esté
suficientemente claro, este es el momento de hacerlo. Ponga por escrito
la especificación de tales ficheros, incluyendo el nombre que dará a las
variables y, en su caso, el que tendrán en el disco o almacenamiento
externo. Esto puede concretarse quizás a la definición de algunas
estructuras (![]() 4.5).
En esta fase es posible que tenga que repreguntar alguna cosa que se pasó por alto.
4.5).
En esta fase es posible que tenga que repreguntar alguna cosa que se pasó por alto.
Teniendo ya una imagen más o menos clara de lo que hará su programa, si
éste es mediano o grande, es posible que todavía tenga que realizar
una labor previa antes de ponerse a escribir el código: diseñar a grandes rasgos cuales serán los módulos
del programa; módulos que se corresponderán aproximadamente con la
distribución del código en ficheros fuente independientes. Quizás
tenga que decidir también si algunas partes aparecerán como librerías
[1]. Recuerde lo indicado al respecto al tratar de los Subespacios de Nombres
(![]() 4.1.11).
4.1.11).
Esta fase es especialmente importante en el caso de programas muy grandes, cuyo desarrollo se reparte entre varios programadores que se encargan de uno o varios de estos módulos. En estos casos, el análisis, la especificación, la subdivisión en partes (con sus especificaciones particulares), y la asignación de estas como tareas a los programadores, lo habrá realizado el jefe de programación y desarrollo.
![]()
§5 Escribir el código
Suponiendo cumplimentados los pasos anteriores, el programador está en condiciones de construir una imagen mental clara de como será esa conexión entre la información de entrada y la salida, es lo que se denomina "espacio" de la solución ("'How' domain"); su forma concreta es justamente el fuente del programa que se pretende. La codificación consiste justamente trasportar a papel (en el lenguaje de programación elegido) la imagen mental de esa conexión.
Para escribir el código fuente de un programa C++ solo se puede utilizar un subconjunto de 96 caracteres del juego total
de caracteres US-ASCII (![]() 2.2.1a).
Son los siguientes [8]:
2.2.1a).
Son los siguientes [8]:
|
Juego de caracteres imprimibles:
|
|
Caracteres
no-imprimibles denominados separadores
Salto de forma (FF); Nueva línea (NL). |
Nota: Para escribir el código solo hace falta un editor de texto plano, aunque las modernas "suites" de programación incluyen editores específicos que están conectados con el depurador, el compilador el enlazador (ver más adelante) e incluso el sistema de ayudas, de forma que, por ejemplo, pueden mostrarnos automáticamente la sentencia en la que se ha producido un error de compilación, o la página correspondiente del manual si pulsamos en una palabra reservada y pedimos ayuda (F1 generalmente). También muestran en diversos colores las palabras clave, los comentarios, Etc. Los más avanzados disponen incluso de opciones que podríamos calificar de "inteligentes", en el sentido que pueden prever cual será nuestro próximo movimiento en función de la sentencia que estamos escribiendo (por ejemplo, ofrecernos una lista de las propiedades y métodos de una clase si nos estamos refiriendo a ella).
Durante la fase de escritura no desdeñe dos puntos:
-
Incluir la mayor cantidad de comentarios y aclaraciones posibles. Cuando se está muy "metido" en el programa todo parece evidente, pero piense que tiene que retocarlo dentro de unos años, quizás entonces le parezca "Chino" y agradecerá haber dejado la mayor cantidad de documentación y aclaraciones al respecto. Incluso si es seguro que no volverá a verlo, piense en el sufrido programador que le seguirá si tiene que habérselas con su código. En este sentido C++ no es precisamente COBOL, aunque afortunadamente permite incluir en el fuente comentarios todo lo extensos que se desee (
 3.1). No caiga tampoco en el error de pensar
que esa información ya está en la documentación escrita que le han
obligado a entregar junto con los fuentes; posiblemente dentro de unos
años Usted mismo no encuentre esos documentos.
3.1). No caiga tampoco en el error de pensar
que esa información ya está en la documentación escrita que le han
obligado a entregar junto con los fuentes; posiblemente dentro de unos
años Usted mismo no encuentre esos documentos. -
Incluir la mayor cantidad posible de rutinas y condiciones de comprobación de errores. Piense que el operador es un "manazas" o que los datos pueden venir con alguna corrupción, error de transmisión, etc. Verifique constantemente que las condiciones son las esperadas (
1.4.5).
Una vez que se tiene el código fuente (en uno o varios módulos), el proceso de traducirlo a instrucciones comprensibles por el procesador (lenguaje máquina) puede hacerse siguiendo dos modelos: los intérpretes y los compiladores [3].
En el caso de lenguajes compilados como C++, el fichero de texto plano (ASCII
![]() 2.2.1a) que contiene el fuente
del programador (con la terminación .C ó .CPP), es sometido a un proceso de
varias fases que terminan en la obtención del ejecutable.
2.2.1a) que contiene el fuente
del programador (con la terminación .C ó .CPP), es sometido a un proceso de
varias fases que terminan en la obtención del ejecutable.
De forma genérica, todo este proceso se denomina "compilación",
aunque es una generalización un tanto incorrecta, ya que la compilación
propiamente dicha es solo una de las etapas intermedias. Sería más
correcto decir "construcción" del ejecutable, aunque por la
extensión y generalización de su uso seguiremos utilizando el término genérico "compilación" para referirnos a él.
Los procesos de construcción del ejecutable se esquematizan en la figura que comentamos a continuación:
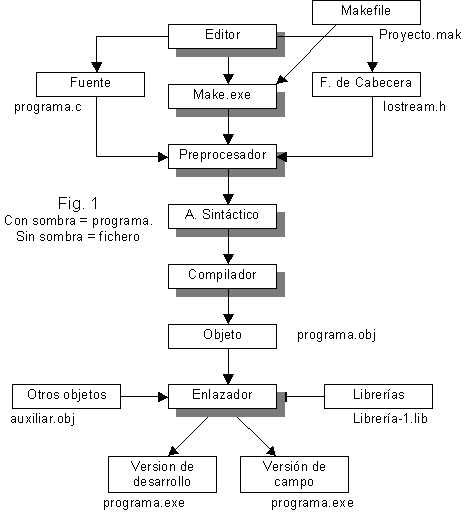
§6 Preproceso
En la primera fase de la compilación; un programa especial, denominado make, es
encargado de iniciar el proceso llamando a los diversos módulos que se
encargan de la construcción del ejecutable (en ![]() 1.4.0 se amplían detalles sobre esta parte del proceso).
El primero de estos módulos es el preprocesador. [13]
1.4.0 se amplían detalles sobre esta parte del proceso).
El primero de estos módulos es el preprocesador. [13]
El preprocesador (![]() 1.4.1)
estudia el texto buscando directivas de preprocesado
(
1.4.1)
estudia el texto buscando directivas de preprocesado
(![]() 4.9.10), por ejemplo sentencias
que pueden ser suprimidas, incluye los ficheros correspondientes a las directivas
#include,
sustituye los #define, elimina los comentarios y expande las macros encontradas en el fuente y
en los propios ficheros incluidos. El resultado obtenido es lo que se denomina unidad de compilación
(
4.9.10), por ejemplo sentencias
que pueden ser suprimidas, incluye los ficheros correspondientes a las directivas
#include,
sustituye los #define, elimina los comentarios y expande las macros encontradas en el fuente y
en los propios ficheros incluidos. El resultado obtenido es lo que se denomina unidad de compilación
(![]() 1.4.2).
1.4.2).
![]()
§7 Análisis sintáctico
Puesto que el fichero fuente está escrito en un "lenguaje" (C++ en este caso) que tiene sus propias reglas de sintaxis (como los lenguajes naturales), el compilador debe comprobar que estas reglas se han respetado. Este análisis ("Parsing") es realizado por el analizador sintáctico [10].
En esta fase se realizan comprobaciones como que los paréntesis están cerrados, que no aparecen expresiones incompletas,
etc. Para realizar esta labor, el "parser" debe identificar los tokens
(![]() 3.2), de forma que el fuente es
tokenizado, esto es, reducido a tokens y separadores.
3.2), de forma que el fuente es
tokenizado, esto es, reducido a tokens y separadores.
El fuente es escaneado, el analizador sintáctico (parser) extrae los tokens, seleccionando el que coincida con la secuencia de caracteres más larga posible dentro de la secuencia analizada [9]. Por ejemplo, la palabra clave external es reconocida como un solo token (identificador de clase de almacenamiento) en vez de seleccionar extern (una palabra reservada) y al (que sería un identificador).
Los separadores (whitespaces) es el nombre genérico dado a los espacios (32), tabulaciones verticales VT (11), horizontales TAB (9) nueva linea NL (10) y retorno de carro CR (13). Los separadores sirven para indicar donde empiezan y terminan las palabras, pero después de esto cualquier separador redundante es descartado. Por ejemplo, las dos secuencias:
int i; float f;
int i;
float f;
son léxicamente equivalentes y el resultado del análisis son las seis palabras siguientes:
int
i
;
float
f
;
El carácter ASCII espacio puede formar parte de cadenas literales (alfanuméricas), en cuyo caso es protegido del proceso de análisis, permaneciendo como parte de la cadena. Por ejemplo:
char name[] = "Playa Victoria";
es reducido a siete tokens, incluyendo una cadena literal "Playa Victoria"
char
name
[
]
=
"Playa Victoria"
;
![]()
§8 Análisis semántico
En lenguajes como el Ensamblador la comprobación se limita al análisis anteriormente señalado; con esto se garantiza que el fuente original es correcto (sintácticamente), es decir, es un escrito correcto desde el punto de vista del lenguaje, otra cosa es que tenga un sentido computacional correcto, o diga tonterías, incongruencias o sinsentidos [6].
Por supuesto la meta del compilador es conseguir descubrir con anticipación (al runtime) el máximo de errores posibles. En los lenguajes de alto nivel, esto se consigue con una cierta comprobación del "sentido" o "significado" del escrito, es el denominado análisis semántico (análisis del significado).
La mejor baza de que dispone C++ para esta segunda comprobación es la comprobación
estática de tipos (![]() 2.2). Es decir, que las variables y las
operaciones entre ellas se usan correctamente; esto supone verificar que las
llamadas a funciones, los valores devueltos por estas y los operandos de las
expresiones corresponden con el tipo que se les supone en cada caso. Por ejemplo:
2.2). Es decir, que las variables y las
operaciones entre ellas se usan correctamente; esto supone verificar que las
llamadas a funciones, los valores devueltos por estas y los operandos de las
expresiones corresponden con el tipo que se les supone en cada caso. Por ejemplo:
int x;
char func();
....
x = func();
En este caso, la primera línea declara que la variable x
es tipo int (entero); la segunda declara que la función fun
devuelve un carácter (char); si una líneas más adelante se pretende igualar la variable x con
el valor devuelto por la función, el analizador semántico estaría en condiciones de asegurar que existe una incongruencia en
las pretensiones del programador, generando el correspondiente mensaje de advertencia o error
![]() .
.
![]()
§9 Generador de código
Todos estos tokens identificados por el analizador sintáctico, son organizados en una estructura como las hojas de un árbol. A continuación, el generador de código recorre este árbol traduciendo sus hojas directamente en código de la máquina para la que se compila [11].
Si se solicita, el compilador también puede en esta fase generar un fichero en lenguaje macro ensamblador para su posible inspección por el programador (este código es también dependiente de la máquina para la que se compila y fácilmente entendible por el humano; puede contener incluso comentarios para facilitar su lectura).
Nota: Los compiladores modernos suelen incluir
opciones que permiten generar código optimizado para el tipo de procesador que
se utilizará. Por ejemplo, el compilador Borland C++ dispone de opciones que permiten generar código
optimizado para procesadores Intel de modelos específicos (![]() 1.4.3a). Como cabría esperar, el compilador
GNU c++ es el que ofrece más posibilidades en este sentido, que incluyen el
tipo de procesador dentro de una larga lista de fabricantes, y dentro de estos
diferentes modelos. En concreto, para la familias Intel i386 y x86-64, permite
elegir entre 20 posibilidades diferentes!!.
1.4.3a). Como cabría esperar, el compilador
GNU c++ es el que ofrece más posibilidades en este sentido, que incluyen el
tipo de procesador dentro de una larga lista de fabricantes, y dentro de estos
diferentes modelos. En concreto, para la familias Intel i386 y x86-64, permite
elegir entre 20 posibilidades diferentes!!.
A veces, después del generador de código puede ejecutarse un optimizador
(peephole optmizer). Este generador de código sería propiamente el compilador,
es decir, el encargado de traducir algo entendible por el humano en código máquina.
En cualquier caso, el resultado es un fichero "objeto", generalmente con la terminación .obj o
.o. También puede ordenarse al compilador que incluya en el "objeto",
determinada información adicional que será utilizada más tarde por el depurador
![]() ,
por ejemplo los números de línea de las sentencias. Cuando se hace
así, se habla de una compilación "provisional" o de "depuración"; distinta de la que se realiza para la
versión definitiva (de campo) del programa en la que no se incluyen este tipo de información que ya no es necesaria.
,
por ejemplo los números de línea de las sentencias. Cuando se hace
así, se habla de una compilación "provisional" o de "depuración"; distinta de la que se realiza para la
versión definitiva (de campo) del programa en la que no se incluyen este tipo de información que ya no es necesaria.
![]()
§10 Enlazado
El último paso en construir un ejecutable es el enlazado.
Recibe este nombre el proceso de aglutinar todos los recursos en un solo fichero ejecutable
(![]() 1.4.4). Estos
recursos son desde luego los ficheros-objeto obtenidos en la compilación de los diversos módulos (ficheros .c)
que componen el programa. Además, si se han utilizado funciones
o clases de librería [1] (como es casi seguro), el enlazador
("Linker") es el programa encargado de incluir los módulos adecuados en el fichero ejecutable final.
1.4.4). Estos
recursos son desde luego los ficheros-objeto obtenidos en la compilación de los diversos módulos (ficheros .c)
que componen el programa. Además, si se han utilizado funciones
o clases de librería [1] (como es casi seguro), el enlazador
("Linker") es el programa encargado de incluir los módulos adecuados en el fichero ejecutable final.
Así pues, la función primordial del enlazador es resolver todas las referencias que puedan existir en el programa, es decir: que cada invocación a un valor o a una función corresponda una dirección donde se encuentra el recurso correspondiente, y que estén todos contenidos en un solo fichero que pueda ser cargado y ejecutado por el Sistema Operativo.
Eventualmente algunos recursos pueden estar en otros ficheros distintos del ejecutable, librerías
de enlazado dinámico ![]() (en Windows se denominan DLLs). En cuyo caso el enlazador también
incluirá las direcciones y convenciones de llamada adecuadas para que puedan
ser traídos a ejecución desde el programa principal.
(en Windows se denominan DLLs). En cuyo caso el enlazador también
incluirá las direcciones y convenciones de llamada adecuadas para que puedan
ser traídos a ejecución desde el programa principal.
![]() Por último, el enlazador se encarga de insertar en el
ejecutable un trozo de código especial: el módulo inicial, que es el encargado de iniciar la ejecución
(
Por último, el enlazador se encarga de insertar en el
ejecutable un trozo de código especial: el módulo inicial, que es el encargado de iniciar la ejecución
(![]() 1.5).
1.5).
Hay que tener en cuenta que generalmente el enlazador puede producir diversos tipos de resultados:
§10.1 Versión de depuración
Se trata de una versión en la que dentro del propio ejecutable, se incluye información adicional no estrictamente necesaria para la ejecución sino para la depuración (por ejemplo los números de línea del código fuente que corresponde a cada sentencia). Estos ejecutables permiten la ejecución en un modo especial, en la que por ejemplo, pueden ejecutarse las sentencias paso a paso, o que el programa se detenga al llegar a diversos puntos establecidos de antemano; ver el contenido de las variables, el estado de la pila y otros aspectos internos muy útiles cuando se intentan depurar errores de tiempo de ejecución. Esto se consigue porque el programa corre bajo control de otro programa que actúa de controlador de la ejecución, es el depurador ("Debugger").
Nota: El depurador puede ser en realidad un módulo adicional al de inicio,
inserto en el ejecutable, que se inicia antes que la propia función main
(![]() 4.4.4),
de forma que puede controlar la ejecución. Por esta razón entre otras,
las versiones de depuración son mayores (en tamaño del fichero) que las definitivas o "de campo"
[12].
4.4.4),
de forma que puede controlar la ejecución. Por esta razón entre otras,
las versiones de depuración son mayores (en tamaño del fichero) que las definitivas o "de campo"
[12].
§10.2 Versión de publicación
Es la versión definitiva que saldrá al público (se entregará al usuario). Se distingue de las versiones internas en que no incluye información para depuración. Es buena práctica incluir en cada versión publicada información sobre el número de versión del programa y de compilación (esto suele venir indicado en la siguiente forma: Versión xx.yy.zz build nnn).
Generalmente los programas sufren muchas modificaciones a lo largo de su vida
(corrección de errores, perfeccionamientos, versiones para diversas
plataformas, etc), y es preciso identificarlos. Es costumbre hablar de
"versiones", que se identifican por grupos de números separados por
puntos. Por ejemplo: Versión xx.yy.zz.
Cada fabricante de software, grupo de trabajo o programador, utiliza una
convención, estableciéndose que tipo de cambios dan lugar a diferencias de
versión en el grupo de cifras xx; en el yy
o en el zz. Generalmente se acepta que los cambios de mayor nivel (xx)
representan versiones totalmente nuevas del programa; que requieren incluso
rescribir los manuales de uso. Los cambios menores corresponden a
modificaciones en el grupo yy (por ejemplo
utilizar otras versiones de las librerías o distinto compilador); finalmente
los cambios de detalle representan modificaciones en el grupo zz.
Viene a representar cambios mínimos, que no merecen una alteración del
último grupo de cifras [7], pero cambios al fin y al cabo (cuando se recompila es
porque algo ha cambiado, aunque sea un comentario en el fuente). Es
también costumbre incluir un último identificador: El número de
compilación o construcción ("build" en la literatura inglesa); es
un número progresivamente creciente para cada compilación distinta. A
título de ejemplo, en la página adjunta se muestra la clasificación
utilizada para las sucesiones versiones de los productos de un conocido
fabricante (![]() Designación de versiones).
Designación de versiones).
§10.3 Librería
En las páginas siguientes veremos que como resultado de la "compilación", no siempre se desea conseguir un ejecutable; al menos no en el sentido tradicional del término, sino una librería (de las que existen varios tipos), o un fichero objeto.
En lo que respecta al lenguaje C++, existen dos tipos fundamentales: Estáticas y Dinámicas.
Las primeras son colecciones de ficheros precompilados, cuyo código puede ser
añadido a un ejecutable en el proceso de enlazado (los ficheros de la
Librería Estándar ![]() 5
que acompañan a los compiladores C++ son de este tipo). Las segundas
son auténticos ejecutables externos que son invocados desde otro ejecutable y
devuelven el control a este cuando terminan su ejecución. Más detalles al respecto en: (
5
que acompañan a los compiladores C++ son de este tipo). Las segundas
son auténticos ejecutables externos que son invocados desde otro ejecutable y
devuelven el control a este cuando terminan su ejecución. Más detalles al respecto en: (![]() 1.4.4a).
1.4.4a).
![]() §11
Errores
§11
Errores ![]() Volver al principio (rescribir el código)
Volver al principio (rescribir el código) ![]()
La verdadera prueba de fuego del programador se presenta cuando lanza la orden de compilar y enlazar su programa. Todos los módulos involucrados en los pasos anteriores, compilador, analizador sintáctico y enlazador pueden detectar errores en nuestro código y mostrar los mensajes correspondientes.
§11.1 Tipos de errores
En cuanto al momento en que se producen, son básicamente de tres tipos:
-
De tiempo de compilación. Se engloban aquí los errores detectados por preprocesador, el analizador sintáctico y el propio compilador. Los hay meramente sintácticos, por ejemplo un paréntesis no cerrado; también de tipo lógico, por ejemplo la referencia a una variable no declarada previamente, etc. etc.
-
De tiempo de enlazado. Son detectados por el enlazador. Por ejemplo una llamada a función cuya definición no aparece por ninguna parte (el enlazador no es capaz de encontrarla en los directorios que tiene asignados como "normales" para buscar); también la inversa: dos funciones del mismo nombre situadas en dos módulos (fuentes) distintos (la referencia aparece duplicada).
-
De tiempo de ejecución (runtime). Existe finalmente una última clase de errores: los que se producen cuando se ejecuta el programa; son precisamente los más difíciles de diagnosticar y verificar, sobre todo en aplicaciones grandes (los relativos a "pérdidas misteriosas" de memoria y punteros descontrolados son especialmente temibles).
§11.2 Gravedad de los errores
Los errores producidos durante la compilación son de dos tipos, según su gravedad:
-
Errores fatales ("Errors"): Son errores graves, el proceso no puede continuar y es detenido después de mostrar la información pertinente.
-
Advertencias ("Warnings"): No son errores graves pero si circunstancias sospechosas o inusuales de las que el compilador entiende que merecen una advertencia por si es algo que se nos ha escapado inadvertidamente (por ejemplo: Una variable declarada que no se utiliza para nada más). En estos casos, el proceso continua y si no hay errores graves se construye un ejecutable.
En todos los casos el aviso incluye indicación del fichero ("fuente" .C/.CPP), el número de línea, y el nombre de la función donde se produce el error, así como una explicación más o menos clara de su motivo. En principio pueden ser cuestiones banales, como haber olvidado poner un punto y coma ; al final de una sentencia (muy corriente en los que estamos acostumbrados a programar en otros lenguajes). En otros casos los mensajes son especialmente crípticos, sobre todo para el profano, pero poco a poco los entendemos mejor y podemos aprender mucho de ellos si prestamos la debida atención y entendemos su "porqué".
Recordar que todos los compiladores disponen de opciones para modificar el número y tipo de los errores y advertencias ("Warnings") que aparecen. Respecto a los primeros, puede instruirse al compilador para que suspenda la actividad al aparecer el primer error, o que continúe hasta que aparezca un número determinado de ellos. Respecto a los avisos, puede ordenarse que no muestre ninguno, o que sea más o menos benevolente en determinados aspectos. Por ejemplo, puede indicarse que la comprobación siga estrictamente el estándar C++ y que avise de cualquier desviación al respecto (los compiladores suelen permitir ciertas "peculiaridades" que no son estándar).
Nota: La descripción e información acerca del error o advertencia, dependen de la plataforma, pero hemos de señalar que existen notables diferencias en cuanto al grado de desarrollo de los diversos compiladores, en especial respecto a los "Warnings". Por ejemplo, en este sentido el Compilador Borland C++ 5.5 es mucho menos riguroso que el producto homólogo de Microsoft, cuyo sistema de verificación es con mucho superior al del primero, de forma que no es infrecuente que advertencias más o menos serias e incluso algunos errores advertidos por Visual C++ 6.0 sean totalmente ignorados por Builder. A su vez los errores y advertencias señalados por el compilador GNU Cpp suelen ser más explicativos que los señalados por Borland o Visual (que en este sentido son más crípticos).
§11.3 Generalidades sobre los errores de compilación
Respecto a los errores de compilación, es importante hacer una advertencia al neófito: Con frecuencia el compilador nos informa de error en una línea más abajo de donde está verdaderamente. Por ejemplo, olvidar un punto y coma de final de sentencia puede dar lugar a que el compilador nos informe de un error incomprensible dos o tres línea más abajo.
Cuando se realizan modificaciones en fuentes grandes y no se tiene mucha práctica, es preferible realizar cambios pequeños y compilar sistemáticamente después de cada uno. Así sabremos que el error corresponde a lo último que hemos tocado. Hay veces en que quitar una simple coma en una sentencia produce una listado de 15 o 20 errores en líneas siguientes. !Súbitamente nada tiene sentido para el compilador !!. [5]
En las asignaciones del tipo:
Lvalue = Rvalue;
en las que intentamos asignar un valor Rvalue (![]() 2.1 que puede ser el resultado de una expresión) a un
Lvalue
(
2.1 que puede ser el resultado de una expresión) a un
Lvalue
(![]() 2.1),
son muy frecuentes los errores en que el compilador produce un mensaje del siguiente aspecto:
2.1),
son muy frecuentes los errores en que el compilador produce un mensaje del siguiente aspecto:
Error .... Cannot convert 'xxxxx' to 'yyyyy' in function ....
Lo importante a reseñar aquí, es que las expresiones xxxxx e yyyyy
informan sobre el tipo de objeto que hay en cada lado de la expresión de asignación.
Nota: En el capítulo dedicado a los tipos de datos
(![]() 2.2) se describe detalladamente
como el compilador clasifica los objetos según su tipo.
2.2) se describe detalladamente
como el compilador clasifica los objetos según su tipo.
En las asignaciones, el Lvalue debe recibir un valor de su mismo tipo. Si el tipo del
Rvalue no concuerda
con él, el compilador puede intentar adecuarlo, pero si esto no es posible,
se produce un error como el señalado. En él se nos indica que el tipo xxxxx,
que corresponde al Rvalue (el resultado de la expresión a la derecha del operador = ), no puede ser
convertido al tipo yyyyy del Lvalue.
Hay que advertir que las expresiones xxxxx e yyyyy
están codificadas. Cada compilador utiliza un algoritmo interno para designar cada uno de los innumerables tipos que
puede existir en C++. En concreto, la designación utilizada en estos mensajes es la misma que utiliza en el operador
typeid (![]() 4.9.14). En
situaciones difíciles, es mucha la información que puede obtenerse de estas expresiones si se observan detenidamente.
4.9.14). En
situaciones difíciles, es mucha la información que puede obtenerse de estas expresiones si se observan detenidamente.
Aunque la comprobación estática de tipos, y del cumplimiento de las reglas
sintácticas realizada por el compilador, resultan muy eficientes en lo que
respecta a la detección de errores, en realidad, el trabajo dista de ser
completo y suficiente. Existen multitud de circunstancias potencialmente
erróneas que son pasadas por alto. En especial las relacionadas con pérdidas
de memoria; existencia de punteros descolgados; bucles infinitos; objetos
declarados pero no utilizados, y un largo etcétera. Algunos de estos
errores pueden permanecer agazapados en el código y solo aparecer en
circunstancias muy especiales, incluso después de que la aplicación haya sido
rodada largo tiempo sin contratiempos. Muchas de estas circunstancias
pueden evitarse, o al menos mitigarse, siguiendo ciertas pautas y
recomendaciones "de buena práctica", muchas de las cuales están
contenidas en la obra TC++PL de Stroustrup; la mayoría en forma de advertencias
sobre cosas que "no" debe hacerse. Sin embargo, el problema
persiste, máxime en un lenguaje como C++ plagados de peligros potenciales que
acechan en el arcén, y con el que es posible "volarse la pierna
completa".
Para reforzar la calidad del código y prevenir errores posteriores (de run-time), se han creado multitud de herramientas. Entre las más conocidas se encuentran las siguientes:
- Lint, denominadas así en atención a que tienen su origen en una utilidad de este nombre (lint) desarrollada inicialmente en el entorno Unix. Estas utilidades se ejecutan sobre el fuente sin compilar (no confundirlas con los depuradores "debugger" -de run-time-, aunque también sirven para "depurar" el código); comprueban la sintaxis y errores en los tipos de datos de forma más concienzuda y profunda que los compiladores C/C++, y avisan de gran cantidad de peligros potenciales; incorrecciones; desviaciones sobre las reglas universalmente aceptadas como de "buena práctica", etc. Actualmente han llegado a un elevado nivel de sofisticación, de forma que un buen Lint puede evitarnos muchas horas de depuración. En realidad es una herramienta que no debería faltar en el taller del programador profesional.
- cb. Esta utilidad, originaria del SO AIX, reformatea el código
fuente contenido en un fichero y lo vuelca sobre el dispositivo estándar de
salida (stdout
5.3) utilizando un formateo basado en
sangrados y espaciados, que ayudan a interpretar la estructura del código.
- cflow. Esta utilidad, originaria del SO AIX, analiza el contenido de un fichero objeto C/C++ y proporciona en la salida estándar (stdout) un gráfico de sus referencias externas.
- cxref. Esta utilidad, análoga a las anteriores, analiza los fuentes C/C++ y genera una tabla con todos los símbolos encontrados en cada fichero, incluyendo los nombres de los parámetros formales de las funciones (contenidos en la definición de la función). La tabla es mostrada en el dispositivo estándar de salida (stdout), e incluye el sitio en que cada referencia se ha resuelto (suponiendo que la definición esté en el código analizado).
Si está interesado en las características y posibilidades de
estos productos, la mayoría comerciales y algunos muy costosos, aparte de la
correspondiente búsqueda en Google, existe un interesante artículo de Scott
Meyers (uno de los "Gurus" del C++) y Martin Klaus titulado "A First Look at C++ Program Analyzers",
en el que se repasan las cualidades y características de distintos
paquetes, incluyendo una evaluación de su comportamiento frente a lo que el
autor considera deseable. Aparecido en el número de Febrero de 1997 del Dr.
Dobb's Journal, existe una versión de pre-publicación accesible on-line, que
es incluso más completa que el artículo publicado (probablemente debido a
las exigencias de maquetación de la revista):  www.aristeia.com.
www.aristeia.com.
Uno de los productos punteros y más antiguos, es el de Gimpel Software
www.gimpel.com;
esta empresa dispone de dos versiones denominadas PC-Lint y FlexeLint. La
primera para Windows, la segunda, más general, para cualquier entorno que
soporte un compilador C, incluyendo Unix y Linux. Si tiene interés en
comprobar más de cerca el tipo de información que proporcionan estas
utilidades, en el sitio de este fabricante existe una sección denominada Bug
del mes ("Bug of the month") en la que se exponen ejemplos de
código, junto con el resultado del análisis (después de pulsar un
botón). Además de súmamente instructivos, los casos propuestos pueden
servirle para auto-evaluar sus conocimientos de C++ al respecto. A mi
entender también pueden constituir una magnífica fuente de inspiración para
los enseñantes que busquen material para ejemplo o evaluación (sed piadosos
en los exámenes porque algunos son realmente para niveles avanzados. No se
puede pretender que después de un semestre de estudio, el alumno esté
en condiciones de adivinar correctamente el "bug C/C++ del mes" :-)
§11.4 Errores de ejecución
Para los errores de tiempo de ejecución se requieren estrategias especiales. En principio, durante la fase
de comprobación inicial, se tienen las ofrecidas por el depurador
![]() .
Prácticamente todos los entornos de desarrollo disponen de un depurador más o
menos potente y sofisticado. Puede afirmarse que el depurador es otra
herramienta que no debe faltar en el arsenal de cualquier programador
profesional, en especial porque hay errores que son prácticamente imposibles de
diagnosticar y corregir sin su ayuda.
.
Prácticamente todos los entornos de desarrollo disponen de un depurador más o
menos potente y sofisticado. Puede afirmarse que el depurador es otra
herramienta que no debe faltar en el arsenal de cualquier programador
profesional, en especial porque hay errores que son prácticamente imposibles de
diagnosticar y corregir sin su ayuda.
Como se ha indicado, el depurador incluye en el ejecutable un código especial que realiza las funciones de depuración deseadas, pero aparte de los que podríamos denominar estándar (cuyos módulos son incluidos en durante la fase de enlazado del ejecutable), existen herramientas específicas que analizan el ejecutable y son capaces de detectar determinados errores e inconsistencias. Estas herramientas realizan su trabajo durante la ejecución, para lo que modifican el código a analizar incluyendo determinados módulos que les permiten controlar el desarrollo de la ejecución (se dice que "instrumentan" el código). La forma de realizar esta "instrumentación" depende de la herramienta: puede realizarse durante la compilación ("compile-time"), añadiendo código que no aparece en el fuente; durante el enlazado ("link-time"); durante la carga ("load-time"), cuando el ejecutable es acomodado en memoria, o antes de la carga, sobre cualquier ejecutable listo para ser usado. Generalmente estas herramientas controlan la ejecución, toman nota de las incidencias, y finalmente proporcionan un informe de las mismas cuando la ejecución finaliza.
Nota: no existe una denominación unificada para este
tipo de productos. Quizás el más conocido es es BoundsChecker, de Numega
www.numega.com
(actualmente aparece como Compuware). También puede intentar una
búsqueda en Google bajo el epígrafe "Memory debugger".
Después de todas las medidas preventivas ya reseñadas, cuando finalmente, después de las pruebas de "laboratorio" damos
por bueno el programa, este queda merced a si mismo; a la calidad de su propio
mecanismo de defensa. Como errar es humano, los diseñadores del C++
pensaron que a pesar de la programación más cuidadosa, siempre pueden
presentarse circunstancias excepcionales o imprevistas. Para poder
hacerles frente, dotaron al lenguaje de opciones especiales con las que tratar
este tipo de situaciones, de forma que pudiese seguir todo bajo control;
estos recursos específicos se exponen con detalle en el capítulo dedicado al Tratamiento de Excepciones
(![]() 1.6).
1.6).
§12 Recursos
Ya hemos señalado que para construir un programa C++ basta un editor de texto plano y un compilador C++ para la máquina y Sistema en que deba ejecutarse, y que en el término "Compilador" incluimos todas las herramientas auxiliares, enlazador, librerías, etc.
Por supuesto que en este sentido, las plataformas comerciales, en especial las versiones denominadas "Enterprise", ofrecen unas prestaciones inigualables, incluyendo potentes depuradores, diseño gráfico de elementos con capacidad de arrastrar y soltar ("dragg and drop") elementos, y conjuntos preconstruidos de clases que simplifican extraordinariamente la construcción de determinados aspectos de las aplicaciones. Por ejemplo, el manejo de bases de datos o comunicaciones. En esta categoría podemos incluir productos como C++Builder de Borland o Visual C++ de Microsoft para el entorno Windows.
En la página dedicada a los Compiladores encontrará algunas referencias (![]() Compiladores).
Compiladores).
Si desea saber más sobre aspectos relacionados con la compilación, preproceso, análisis sintáctico y semántico, traducción del código, etc, mi consejo es que consulte "Compiladores y Procesadores de Lenguajes" [Jiménez-04]
[1] En el argot de programación,
"función de librería" se refiere a un recurso prefabricado; trozos
de código, generalmente en forma de funciones o clases que otros han escrito,
que incluimos en nuestro programa. La confección de programas se parece a
la construcción de un edificio en el que cada vez más se utilizan elementos
preconstruidos (algunas veces normalizados), que facilitan y aceleran la
construcción. Suelen ser de dos clases: incluidas
en el compilador (lenguaje utilizado), que en caso del C++ están incluidas en la denominada Librería Estándar
(![]() 5), y de terceras partes;
librerías especializadas en cuestiones muy concretas que pueden adquirirse para no tener que escribir por nosotros mismos
rutinas que otros (que además saben mucho sobre el tema), se han encargado de escribir y comprobar. Por ejemplo:
librerías gráficas, de comunicaciones, estadísticas, para escribir códigos de barras en una impresora, Etc.
5), y de terceras partes;
librerías especializadas en cuestiones muy concretas que pueden adquirirse para no tener que escribir por nosotros mismos
rutinas que otros (que además saben mucho sobre el tema), se han encargado de escribir y comprobar. Por ejemplo:
librerías gráficas, de comunicaciones, estadísticas, para escribir códigos de barras en una impresora, Etc.
Las modernas "suites" de programación C++ incluyen completísimas librerías en las que están resueltas la mayoría de las situaciones que habitualmente se suelen presentar en la programación normal. Precisamente el entorno C++Builder de Borland-Imprise es un claro ejemplo. El paquete estándar comprende un entorno gráfico de programación (IDE) para Windows, que incluye un potente conjunto de librerías en forma de "herramientas". Es un producto comercial con un precio determinado. En cambio, el compilador, el depurador y la Librería Estándar se suministran gratis. Es decir, se asume que el valor comercial está en el entorno gráfico integrado y en las librerías adicionales.
[2] Seguramente se me ocurre lo de "cliente" por deformación profesional; por supuesto el cliente podemos ser nosotros mismos, el jefe, el profesor de la asignatura, Etc.
[3] Con objeto de mejorar la velocidad de ejecución (tradicionalmente lenta), algunos intérpretes, utilizan en realidad un modelo híbrido. Obtienen un seudo-ejecutable intermedio, mediante un preprocesado seguido de un "parsing", con lo que se obtiene un código "tokenizado" que es el que se entrega realmente al intérprete.
[4] A la hora de redactar estas líneas parece estar muy de moda una técnica denominada Programación Extrema (eXtreme programming), cuya filosofía se basa en 12 principios o mandamientos, alguno tan pintoresco como el de las "40 horas semanales", según el cuál la mejor manera de aumentar el rendimiento es que los programadores "solo" trabajen 40 horas a la semana, pues está científicamente demostrado que un trabajador fresco produce código de mejor calidad que uno cansado. A mí particularmente, este tipo de consejos me recuerdan el de los libros de instrucciones americanos para el microondas: "No se aconseja utilizarlo para secar a su mascota" :-))
[5] Como consecuencia, después de algunos años de oficio, los programadores suelen (solemos) ser gente un poco "tocada de la azotea". No cabe duda que pasar años viviendo en un mundo donde no da igual un punto que una coma en un millón de líneas de código termina imprimiendo carácter. El resultado es que el resto de la gente "normal" no entiende muy bien porqué somos tan maniáticos y puntillosos en algunos asuntos, ya que afortunadamente (¿?), el mundo real suele ser de lógica más "borrosa" (a veces, tan borrosa que apenas se ve nada...).
Nota: Esto de la lógica "Borrosa" viene a cuento y recuerdo de un amigo. Una persona de un gran talento natural que no ha tenido ocasión de recibir formación académica (es mecánico y apenas ha ido a la escuela). En cierta ocasión delante de unas cervezas intenté explicarle las diferencias entre la lógica binaria y la difusa ("Fuzzy logic"). Días después conversaba él con otras personas y me sorprendió como introducía el concepto de la lógica difusa con total oportunidad y como si fuese una cosa sabida de toda la vida. Solo había cambiado una palabra; "borrosa" en lugar de difusa.
[6] Las circunstancias son exactamente idénticas a las que se presentan en los lenguajes naturales. También en estos es posible construir frases sintácticamente correctas pero carentes de sentido (los políticos saben mucho de esto).
[7] En esta nomenclatura, una versión 2.4.10 es anterior a la 2.13.0, que a su vez es anterior a la 12.3.
[8] Para resolver el problema de que algunos de estos símbolos no aparecen en los
teclados de determinados idiomas (por ejemplo, la tilde ~ en los teclados
españoles) se recurrió a representarlos mediante ternas de otros caracteres, los denominados trigrafos
(![]() 3.2.3e).
3.2.3e).
[9] Esta regla de análisis es conocida como de Max Munch; en realidad no es ningún personaje real, sino un convenio adoptado por los integrantes del primer Comité de Estandarización del lenguaje.
[10] En general, un "parser" es un programa diseñado para analizar un documento.
[11] "On average, each line of code in a system programming language translates to about
five machine instructions, compared to one instruction per line in assembly language (in an informal analysis of eight C files
written by five different people, I found that the ratio ranged from about 3 to 7 instructions per line; in a study of
numerous languages Capers Jones found that for a given task, assembly languages require about 3-6 times as many lines of code
as system programming languages). Programmers can write roughly the same number of lines of code per year regardless of
language, so system programming languages allow applications to be written much more quickly than assembly language".
John K. Ousterhout. "Scripting: Higher Level Programming for the 21st Century"
![]() www.tcl.tk
www.tcl.tk
[12] Como botón de muestra, señalar que en una aplicación C++ típica Windows, cuyo ejecutable resultaba de 631 KBytes en su versión "de campo", la inclusión de la información necesaria para depuración hizo aumentar su tamaño hasta 3.257 KBytes (Compilador GNU gcc-g++ 3.4.2 para Windows -incluido en Dev-C++ -)
[13] Para los interesados en aspectos adicionales sobre la compilación puede ser interesante el artículo "C++ compilation speed" (en Inglés) de Walter Bright publicado en
Dr.
Dobbs.