1.8 Estructura de la información (II)
§4 Estructuras lógicas
Al pensar en un "contenedor" de información la idea más simple es la de un saco que lo contenga todo, pero es fácil intuir que esta forma no es demasiado adecuada para recuperar la información. El cajón de sastre puede ser cómodo para almacenar, no para recuperar.
Desechada la anterior, la segunda idea sería tratar de almacenar juntos datos homogéneos (aunque no hay inconveniente teórico para que los tales datos sean todo lo complejos que se desee). Por ejemplo, en una aplicación real se almacenarían separadamente los datos de clientes; de proveedores, de artículos, etc. A su vez cada uno de estos almacenamientos tendrían información compleja aunque relacionada. Por ejemplo, el fichero o tabla de clientes contendría nombre, domicilio, teléfono, dirección, e-mail, web, etc de cada cliente. Lo mismo con los proveedores, artículos, etc.
A estos conjuntos de datos que se almacenan juntos, los denominamos unidades de almacenamiento (generalmente este es el enfoque utilizado). Por ejemplo, siguiendo con el supuesto anterior, almacenamos juntos los datos de clientes, y cada cliente es una unidad de almacenamiento. Aunque pueda estar constituido a su vez por un conjunto muy grande de datos, se graban o borran los datos de un cliente cada vez, esta unidad no es divisible (no puede existir medio cliente, aunque algunos de sus registros si pueden estar vacíos).
Nota: La unidad de almacenamiento corresponde con el concepto tradicional de registro, o con el de fila, si se utiliza la terminología de las bases de datos relacionales.
Respecto como están relacionadas entre sí estas unidades de almacenamiento, las estructuras de datos comúnmente
utilizadas son cuatro: Colas; Pilas; Listas enlazadas y Árboles
[4] que comentamos en este capítulo, y que con
variaciones más o menos sofisticadas dan origen a todas las demás.
Nota: Se considera que las tres primeras pertenecen a un grupo denominado estructuras
lineales, en el que existen otros tipos, por ejemplo matrices
(![]() 4.3), tablas hash y deques
(
4.3), tablas hash y deques
(![]() 5.1.1). Los árboles
pertenecen al grupo de los grafos en el que existen varios subtipos.
5.1.1). Los árboles
pertenecen al grupo de los grafos en el que existen varios subtipos.
§4.1 Colas: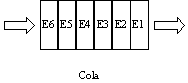
Las colas ("Queues") son sucesiones de registros [2] contiguos dispuestos de forma que es fácil añadir un nuevo elemento (que se coloca después del último) y/o acceder o eliminar el primero. La forma en que están construidas las hace parecerse a una tubería, el primer agua que entra es la primera que sale. Esta forma de acceder a la información se denomina FIFO ("First In First Out") primero en entrar primero en salir.
Estas entidades corresponden a lo que en matemáticas se conoce como líneas de espera, y su estudio teórico, conocido como teoría de colas, es muy importante en transporte y telecomunicación (una modalidad de transporte). A título de curiosidad podemos citar que incluso existe un lenguaje de programación denominado Oroogu, cuyo único tipo de datos es una cola.
Sus características básicas pueden sintetizarse cuatro palabras: datos contiguos, ordenación FIFO.
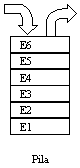 §4.2 Pilas:
§4.2 Pilas:
Las pilas ("Stacks") son igualmente sucesiones de registros contiguos. Podemos imaginar que se van "apilando" sucesivamente uno sobre el otro (de ahí su nombre). Esta disposición hace que sea fácil añadir un nuevo elemento al final, accederlo o eliminarlo. Esta forma de acceso a la información se denomina LIFO ("Last In First Out") último en entrar primero en salir.
Podemos imaginar que tanto en las colas como en las pilas, insertar o eliminar un elemento intermedio, es un proceso complicado si no imposible.
Sus características se resumirían en: datos contiguos, ordenación LIFO.
§4.3 Listas enlazadas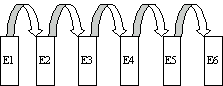
Las listas enlazadas ("Linked list") son conjuntos de registros conceptualmente contiguos pero que físicamente no tienen porqué estarlo (aunque lo normal es que si lo estén); su orden lógico no tiene nada que ver con el orden físico de los elementos en el conjunto.
El orden lógico se consigue porque cada elemento de la lista dispone de un puntero que señala al próximo elemento. De esta forma la lista se mantiene ordenada, y es fácil recorrerla en sentido ascendente. Para añadir un nuevo elemento solo hay que establecer en el último un puntero que señale a la posición del nuevo elemento, que queda de este forma transformado en el último.
En la figura anterior se ha representado una de estas listas denominadas simplemente enlazadas.
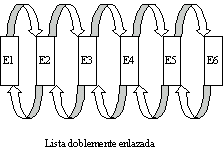
Una variedad de la anterior la constituyen las listas doblemente enlazadas. En este caso, cada elemento dispone de dos punteros, uno al elemento siguiente y otro al anterior. De esta forma la lista puede ser fácilmente recorrida en ambos sentidos, ascendente y descendente.
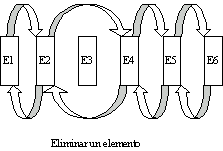 En
este tipo de arreglos es muy sencillo insertar o eliminar un elemento en
cualquier posición, al principio, al final o intermedio, solo hay que
reorganizar los punteros adecuadamente según se ve en las figuras. Lo
normal es que los punteros acompañen a la información contenida en los propios elementos, con lo que evidentemente, en cada
elemento, además de la información pertinente, según el tipo de lista, debe existir espacio adecuado para uno o dos punteros.
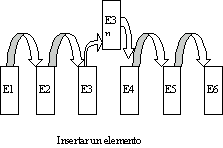
En
este tipo de arreglos es muy sencillo insertar o eliminar un elemento en
cualquier posición, al principio, al final o intermedio, solo hay que
reorganizar los punteros adecuadamente según se ve en las figuras. Lo
normal es que los punteros acompañen a la información contenida en los propios elementos, con lo que evidentemente, en cada
elemento, además de la información pertinente, según el tipo de lista, debe existir espacio adecuado para uno o dos punteros.
Las listas simple y doblemente enlazadas son ampliamente utilizadas. Por ejemplo, los sistemas de ficheros de disco utilizan esta técnica para dar apariencia de continuidad a trozos (clusters) físicamente dispersos en la superficie del disco que componen una sola unidad lógica (fichero) [6].
Como se ha señalado, estas estructuras de datos son adecuadas cuando la información debe mantenerse ordenada, y ser accedida de forma secuencial con posibilidad de insertar y eliminar elementos en cualquier posición.
El tipo de ordenación puede ser cualquiera; desde la denominada "natural", que es simplemente la forma en que se han creado y destruido los elementos de la lista (los jóvenes al final, los más viejos al principio), a cualquier otra basada en otro criterio. Por ejemplo alfabético, según un campo alfanumérico que suponemos existe en cada elemento. En este caso, antes de insertar un nuevo elemento hay que localizar la posición que le corresponde; esto solo puede hacerse recorriendo secuencialmente la lista hasta encontrar la posición adecuada al criterio de ordenación utilizado.
En cuanto a su idoneidad para buscar un elemento en su interior, el caso más desfavorable supone tener que recorrer la totalidad de la lista antes de localizarlo, pero si utilizamos un número suficientemente grande de datos aleatorios, el número de pasos necesario tiende a n/2, lo que significa que por término medio debe recorrerse la mitad de los elementos de la lista antes de encontrar el elemento [3].
[2] Aquí utilizamos "registro" en el sentido de cada uno de los elementos de información que componen la estructura (a su vez pueden tener una estructura interna más o menos compleja). Reciben este nombre cuando las estructuras tienen localización física en soportes externos, discos por ejemplo.
[3] En listas ordenadas es posible utilizar mecanismos más sofisticados, por ejemplo técnicas de búsqueda dicotómica, que pueden reducir sensiblemente el número de pasos necesarios.
[4] Un buen sitio para hurgar en este
tipo de definiciones es el Dictionary of Algorithms and
Data Structures del NIST ("National Institute of Standards and
Technology"), un organismo dependiente del Departamento de Comercio del
Gobierno USA ![]() www.nist.gov
www.nist.gov
[6] Por ejemplo, los sistemas FAT son un ejemplo paradigmático de listas simplemente enlazadas
(![]() H8.1.2d).
H8.1.2d).