5.1 Librería Estándar de Plantillas
§1 Sinopsis
La librería estándar de plantillas, o STL ("Standar Template Library"), siglas por las que se la conoce, es un gran conjunto de estructuras de datos y algoritmos que conforman una parte sustancial de la Librería Estándar C++.
A pesar de que la definición anterior es irreprochablemente correcta, y que el lector puede encontrar una introducción
sobre el significado de los términos "estructuras de datos" y "algoritmos" en el capítulo correspondiente
de esta obra (![]() 1.8). Al estudiante que se asoma por primera vez, una
definición como la anterior posiblemente lo deje más frió que caliente. Digamos entonces que la STL
es en realidad un banco de trabajo construido casi exclusivamente sobre dos
elementos ya existentes en el lenguaje: los tipos abstractos (clases) y
las plantillas ("Templates"). Con estos elementos, su creador y colaboradores (ver nota histórica a continuación
1.8). Al estudiante que se asoma por primera vez, una
definición como la anterior posiblemente lo deje más frió que caliente. Digamos entonces que la STL
es en realidad un banco de trabajo construido casi exclusivamente sobre dos
elementos ya existentes en el lenguaje: los tipos abstractos (clases) y
las plantillas ("Templates"). Con estos elementos, su creador y colaboradores (ver nota histórica a continuación
![]() )
han creado un extraordinario conjunto
de utilidades que comprende estructuras de datos y algoritmos (muy genéricos) para su manejo.
)
han creado un extraordinario conjunto
de utilidades que comprende estructuras de datos y algoritmos (muy genéricos) para su manejo.
Los criterios de diseño de la STL pueden resumirse en dos palabras: generalidad y eficiencia. En palabras de su creador [6]: "STL no es un intento de imponer otro estándar a la sufrida humanidad. Tampoco fue diseñada 'para' ni 'por' un comité. Es el resultado de 15 años de investigación en programación genérica que he realizado en diversos sitios, con diferentes colaboradores, y en diferentes lenguajes de programación. Realicé este trabajo con un objetivo concreto en mente: encontrar un modo de escribir algoritmos de la forma más general, pero de forma que su grado de abstracción no impusiera ninguna penalización en el rendimiento".
En esta librería existen dos aspectos interesantes (apuntados antes) que no son compartidos por muchos otros componentes de la Librería Estándar. El primero es que la STL es un conjunto de algoritmos escritos en C++; es decir: utilizando recursos que ya existen en el lenguaje. El otro aspecto es su alto nivel de abstracción.
Respecto al primero, la consecuencia es que podríamos
evitar utilizarlas en absoluto construyendo nosotros mismos la solución (lo
que sería bastante ingenuo por nuestra parte). Observe que no es el
caso de otras partes de la Librería. Por ejemplo: no podemos prescindir
de la función fopen (para abrir un fichero) porque no existe en el
lenguaje nada que haga tal cosa (probablemente los implementadores del
compilador tuvieron que construir rutinas de llamada al Sistema para construir
esta función). La consecuencia es que la STL es en realidad una enorme
cantidad de código C++ englobado en ficheros de cabecera. Además, como
se apoya extensivamente en el mecanismo de plantillas (![]() 4.12), gran parte del trabajo es realizado en la fase de compilación.
4.12), gran parte del trabajo es realizado en la fase de compilación.
Nota: En realidad la STL está constituida casi exclusivamente de plantillas, al extremo que el propio presidente del comité de estandarización definió a esta librería como "Plantillas con esteroides" [7]. Más de 9000 líneas de código altamente refinado que puede producir código tanto o más eficaz que el que podamos construir nosotros manualmente.
Respecto al segundo punto, su inventor explica [5]: "Una agradable característica de la STL es que el único sitio en que se hace referencia a tipos relacionados con la máquina (algo que hace referencia a punteros o referencias a ellos) se reduce a 16 líneas de código. Todo lo demás, todos los contenedores y algoritmos, se han construido sobre tipos abstractos sin mencionar nada que tenga relación con la máquina".
Alexander Stepanov comenzó a trabajar en la idea germinal de lo que luego sería la STL a finales de la década de 1970, cuando trabajaba en el centro de investigación de General Electric en Schenectady NY junto con Deepak Kapur y David R. Musser. Incluso desarrollaron un lenguaje denominado Tecton que soportara lo que ellos llamaban estructuras genéricas. Stepanov trabajó después en los laboratorios AT&T, donde coincidió con Bjarne Stroustrup y Andrew Koenig. Posteriormente recaló en los laboratorios de Hewlett-Packard de Palo Alto en California, donde en 1992 comenzó a desarrollar la librería de plantillas dentro del proyecto de programación genérica de HP, en el que dirigía a un grupo de colaboradores. Posteriormente se uniría al grupo Meng Lee (Stepanov ha llegado a decir: "After all, STL stands for Stepanov and Lee").
Desde sus inicios Stepanov había intentado plasmar sus ideas en los distintos lenguajes de programación disponibles en el momento. Principalmente Ada, que dispone de algunos conceptos apropiados. Stepanov y Musser publicaron incluso una librería Ada que contenía el resultado de sus investigaciones de entonces, pero Ada es un lenguaje que ha tenido poca aceptación fuera de los círculos del Departamento de Defensa (DoD) y del Gobierno USA.
Por aquel tiempo C++ estaba convirtiéndose en uno de los principales lenguajes de desarrollo de aplicaciones y sistemas, por lo que Stepanov decidió plasmar el resultado de sus investigaciones en HP en dicho lenguaje. El resultado es que las librerías del proyecto de programación genérica de esta compañía estaban escritos en C++.
En 1994 Koenig, que a la sazón era editor del borrador del Estándar, visitó el laboratorio de Stepanov, donde tuvo conocimiento de los trabajos de grupo de programación genérica. Inmediatamente se percató del potencial e importancia de dichos desarrollos por lo que convenció a Stepanov para que lo presentara al comité de estandarización en forma de propuesta con el apoyo de Stroustrup. Finalmente el mismo año fue incorporada oficialmente al borrador del Estándar y aprobada más tarde con pequeñas modificaciones.
Hay que añadir que en Agosto de 1994 Hewlett Packard puso a disposición del público (en Internet) su librería genérica C++, que contenía los trabajos de Stepanov y Lee presentados en forma de borradores al Comité. El resultado de este acto de liberalidad de HP, que solo realizan grandes compañías en contadas ocasiones, fue que su librería genérica ha sido la base de la mayoría de implementaciones realizadas por los diversos fabricantes de compiladores C++ para adaptarse al Estándar.
Quizás uno de los aspectos más significativos de este proceso ha sido el desarrollo del proceso en sí mismo. Generalmente los comités de estandarización se limitan a regularizar situaciones que han ido desarrollándose de forma paulatina, y cuya aceptación y utilización han ido haciéndose general de forma más o menos progresiva. Como hemos señalado, el caso de la STL de C++ ha sido justamente a la inversa. La herramienta fue sacada de un nicho de investigación muy reducido para ser estandarizada después de ligeros retoques. Antes de esto, prácticamente "nadie" en el mundo de la programación sabía nada acerca de tales librerías.
§2 Un nuevo estilo de programación
Precisamente lo que caracteriza y distingue a STL del resto
de librerías C/C++ es que utilizan un nuevo y avanzado paradigma de
programación: la programación genérica.
Aunque pueda causar cierta sorpresa, esta parte del Estándar no es orientada
a objetos y el hecho no es fortuito ni mucho menos, sino resultado de largas
cavilaciones por parte de los diseñadores, de forma que, aunque repitamos una y otra vez que la encapsulación
de datos y procedimientos es una de las ventajas principales de la POO
(![]() 1.1), en esta parte de la Librería
Estándar, las estructuras de datos y ciertos algoritmos genéricos
para su manipulación se han mantenido deliberadamente separados.
1.1), en esta parte de la Librería
Estándar, las estructuras de datos y ciertos algoritmos genéricos
para su manipulación se han mantenido deliberadamente separados.
La explicación "oficial" de esta decisión suele ser del siguiente tenor [2]: "Este diseño proporciona ciertas ventajas, como un código más pequeño y la flexibilidad de usar algoritmos con punteros y matrices C++ junto con objetos convencionales. También resulta en un código más eficiente y de ejecución más rápida, proporcionando una aproximación más directa a la resolución de los problemas".
Al estudiante novel y a los que provienen de la programación clásica, que no hayan tenido contacto previo con la POO, afirmaciones como las anteriores les parecerán algo extrañas. Sobre todo después de haber oído hasta la saciedad panegíricos sobre las bondades de la POO y de las clases en particular; hasta el extremo que hay lenguajes como Java en los que no existen funciones como tales, todo son métodos de clases. Además, las descripciones de los componentes de estas librerías STL, sobre todo de los contendores e iteradores (ver más abajo), resultan a "priori" algo difíciles de entender a causa de su alto grado de abstracción. Afortunadamente esta dificultad desaparece una vez que se ha conseguido una visión general de su arquitectura.
Para entender mejor el asunto, quizás convenga hacer una introducción a las razones por las que, en esta parte de la Librería Estándar C++, se ha mantenido la separación de estructuras de datos y algoritmos y en que forma se concreta esta separación.
§3 Librerías genéricas
Hemos señalado (![]() 5)
que las Librerías Estándar son un conjunto de algoritmos que puede utilizar el programador para realizar
determinadas operaciones. Por evidente no es necesario explicar
que estos módulos de programa pretenden ser lo más universales posibles, de
forma que sirvan al mayor número de circunstancias concretas con que se puede
encontrar un programador en su trabajo cotidiano. Es decir, deben presentar el mayor grado posible de abstracción.
5)
que las Librerías Estándar son un conjunto de algoritmos que puede utilizar el programador para realizar
determinadas operaciones. Por evidente no es necesario explicar
que estos módulos de programa pretenden ser lo más universales posibles, de
forma que sirvan al mayor número de circunstancias concretas con que se puede
encontrar un programador en su trabajo cotidiano. Es decir, deben presentar el mayor grado posible de abstracción.
Después de pensar años en el tema, Stepanov y Musser llegaron a la conclusión de que la forma adecuada para tratar la programación relacionada con el manejo de datos, no coincidía totalmente con ninguno de los paradigmas de programación que habían estado de moda hasta el momento: la POO y la programación funcional, sino una combinación de ambas. De un lado una serie de estructuras, denominadas contenedores (que tendrían muchas de las características de las clases de la POO) y de otro una serie de operadores genéricos que actúan sobre ellas, los denominados algoritmos, que se corresponderían con el concepto tradicional de función. El resultado de la conjunción de estos dos paradigmas es una librería excepcionalmente flexible y potente.
Nota: No obstante, ciertas operaciones muy básicas se mantienen asociadas a los contenedores, de modo que estos encapsulan los datos y un limitado repertorio de operaciones sobre ellos al más puro estilo de la POO. Estas operaciones se refieren a crear, copiar y destruir el contenedor, así como añadir o eliminar elementos de su interior. Sin embargo, no ofrecen métodos que, por ejemplo, permitan examinar sus elementos u ordenarlos. Este tipo de operaciones está encomendad a los algoritmos que son funciones globales.
Mejor, y mucho más autorizadas, que nuestras palabras, son las del propio inventor de la librería
[6]: "The past 25 years have seen attempts to revolutionize programming by reducing all
programs to a single conceptual primitive. Functional programming, for example, made everything into a function; the notions
of states, addresses, and side effects were taboo. Then, with the advent of object-oriented programming (OOP), functions
became taboo; everything became an object (with a state).
STL is heavily influenced by both functional programming and OOP. But it's not a single-paradigm library; rather, it's a
library for general-purpose programming of von Neumann computers.
STL is based on an orthogonal decomposition of component space. For example, an array and a binary search should not be
reduced to a single, fundamental notion. The two are quite different. An array is a data structure -- a component that
holds data. A binary search is an algorithm -- a component that performs a computation on data stored in a data
structure. As long as a data structure provides an adequate access method, you can use the binary-search algorithm on
it. Only by respecting the fundamental differences of arrays and binary searches can efficiency and elegance be
simultaneously achieved".
Podemos resumir que la dicotomía contenedor-algoritmo
permite describir estos "operadores" sin preocuparse del contenedor
concreto sobre el que están operando. Es decir: el código resultante de utilizar algoritmos está bastante desligado de los
datos concretos que se están trabajando, lo que da como resultado un código muy
genérico. Otra ventaja de este enfoque del problema, es que
permite adentrarse en lo que se denomina Programación Funcional o genérica, cuyo
objeto es describir qué está
haciendo el programa en cada momento más que cómo
lo está haciendo. Por ejemplo: se dice ordenar (sort) más que como se
hace el sort en cada caso o con cada tipo de estructura de datos.
Para el programador da igual aplicarlo a las letras de una cadena de
caracteres que a los ficheros de un directorio; el sort será
conceptualmente muy parecido en ambos casos, así como sus resultados, aunque
las estructuras de datos sean en uno y otro caso muy distintas. Los detalles,
cómo se realiza en uno y otro caso, son irrelevantes a efectos prácticos.
Nota: Aunque el binomio contenedor/algoritmo es el eje central de la idea de Stepanov (lo que él ha denominado "an orthogonal decomposition of component space"), comprobaremos que su implementación práctica ha obligado a introducir algunos conceptos y entidades adicionales. De hecho, la materialización de estos mecanismos en C++ obligó a introducir algunos conceptos que previamente no existían en el lenguaje. Por ejemplo, todo el sistema de funciones y clases genéricas ("Templates") encuentran su origen en necesidades de la STL.
Como se ha señalado, el objetivo último del diseño de la STL, es conseguir la
máxima abstracción y por tanto generalización, de los algoritmos.
Sin embargo, presenta también sus desventajas. El principal inconveniente de
utilizar directamente la STL es que aumenta la posibilidad de error. La utilización de plantillas hacen
más difícil el diagnóstico y el código puede crecer más de lo esperado [4].
La única forma de minimizar estos problemas es una gran práctica con el
compilador y experiencia con las propias librerías.
§3.1 Contenedores
En realidad los contenedores son clases genéricas (plantillas) pensadas para contener objetos de tipo muy
diverso. Existen varias clases de contenedores que se diferencian entre
sí en el tipo de operaciones que soportan (![]() 5.1.1), aunque pueden ser englobadas en dos grandes
tipos: asociaciones y secuencias.
5.1.1), aunque pueden ser englobadas en dos grandes
tipos: asociaciones y secuencias.
Cada tipo de contenedor pueden ser considerado como una estructura de datos adecuada para determinados algoritmos. De forma que la elección de un contenedor u otro para nuestros datos, depende principalmente de como vayamos a utilizarlos. Por ejemplo, unos contenedores son más adecuados que otros para conjuntos de datos que deben crecer y disminuir de forma dinámica, mientras que otros son especialmente adecuados para insertar o eliminar datos al comienzo o al final; para accederlos de forma aleatoria o secuencial; para accederlos mediante claves; para posibilitar la existencia de datos duplicados; Etc.
Un punto a destacar es que, aunque los contenedores son clases (genéricas), que pueden ser utilizadas para obtener objetos concretos, e incluso utilizarlas como superclases de una jerarquía definida por el usuario. Son clases aisladas e independientes unas de otras. Es decir, no derivan de una única superclase "Container" general y desde luego no todos aceptan el mismo tipo de operaciones.
La declaración de contenedores es muy sencilla. Por
ejemplo, para definir un contenedor tipo vector (una generalización de
las matrices unidimensionales C/C++ ![]() 5.1.1c) que almacene enteros:
5.1.1c) que almacene enteros:
vector<int> miVector;
Para definir un contenedor tipo map (un tipo de matrices asociativas) para cadenas alfanuméricas:
map<string, string, less<string> > capital;
capital["Francia"]="Paris";
capital["España"]="Madrid";
Nota: En la literatura respecto al tema, es frecuente encontrar referencias a los miembros del contenedor (datos) como una "serie" o "secuencia". Esto es debido a que se utilizan a través de punteros, y como en el caso de una matriz, los miembros pueden ser explorados secuencialmente incrementando el puntero inicial una unidad cada vez. Veremos que la forma en que el puntero recorre la secuencia no siempre es la misma. En ocasiones esta secuencia es el orden "natural" en que están colocados los datos (como en el caso de una matriz); en otros casos la secuencia se recorre en función de una clave que actúa como índice.
§3.2 Iteradores
Como las estructuras de datos (contenedores) son clases genéricas, y los operadores (algoritmos) que deben operar sobre ellas son también genéricos (funciones genéricas), Stepanov y sus colaboradores tuvieron que desarrollar el concepto de iterador como elemento o nexo de conexión entre ambos. El nuevo concepto resulta ser una especie de punteros que señalan a los diversos miembros del contenedor (punteros genéricos que como tales no existen en el lenguaje). La figura 1 muestra esta relación. Este diseño ha permitido que los algoritmos adopten la forma de funciones globales que aceptan iteradores como argumentos, a través de los cuales puedan operar sobre los miembros del contenedor [1].
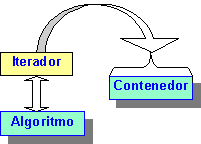
Fig. 1 |
Los iteradores de la STL se materializan en forma de clases definidas en el la cabecera <iterator> que pueden instanciarse para servir a cada binomio contenedor/tipo-de-contenido. Podemos decir de ellos lo mismo que de los contenedores: aunque son clases que pueden usarse para obtener objetos concretos, son aisladas e independientes unas de otras. Es decir, no derivan de una única superclase "Iterator". Sin embargo los contenedores que sirven a una clase concreta si constituyen una jerarquía.
Al igual que los punteros, los iteradores disponen también de un álgebra rudimentaria que permite realizar con ellos ciertas operaciones. El diseño de la STL garantiza que cada iterador que acepta una operación lo hace siempre mediante la misma interfaz. Por ejemplo, los operadores suma ( ++ ) y resta ( -- ) unarias, mueven un iterador de cualquier tipo hasta el próximo o anterior elemento dentro del contenedor asociado. Del mismo modo, la aplicación del operador de indirección * sobre un iterador de cualquier tipo, puede utilizarse para acceder al elemento asociado.
§3.3 Algoritmos
Hemos señalado, que los contenedores pueden ser considerados como estructuras de datos y que los algoritmos
se comportan como operadores que actúan sobre los elementos de estas
estructuras. En el contexto de la STL un algoritmo genérico (![]() 1.2.1)
no pertenece a ningún tipo particular de contenedor. Se comporta
como una función genérica que obtiene información sobre la forma de
manipular los tipos que usa mediante el análisis de los argumentos (iteradores) que se
le pasan. Hemos señalado también que en la STL los algoritmos
adoptan la forma de funciones que incluyen iteradores
entre sus argumentos, lo que les permite manipular los elementos de los contenedores subyacentes.
1.2.1)
no pertenece a ningún tipo particular de contenedor. Se comporta
como una función genérica que obtiene información sobre la forma de
manipular los tipos que usa mediante el análisis de los argumentos (iteradores) que se
le pasan. Hemos señalado también que en la STL los algoritmos
adoptan la forma de funciones que incluyen iteradores
entre sus argumentos, lo que les permite manipular los elementos de los contenedores subyacentes.
La STL ofrece un conjunto de más de 60 algoritmos que puede evitarnos tener que escribir los detalles de ciertas manipulaciones que se repiten una y otra vez. Suelen estar en la cabecera <algorithm> y generalmente su utilización conduce a un código increíblemente rápido y compacto, en sustitución de lo que serían varias páginas de código, si tuviésemos que escribirlo por nuestros propios medios partiendo de cero.
Como en el caso de los iteradores, los algoritmos de la STL utilizan una interfaz homogénea cualquiera que sea el tipo de objeto (contenedor) sobre el que se aplique. Esto permite que los conocimientos obtenidos del estudio de uno de ellos puedan ser extendidos a los demás y que su dominio no sea tan difícil como lo sería de no mantenerse este isomorfismo.
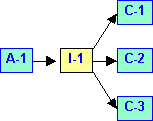
Fig. 2 |
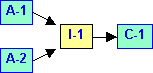
Fig. 3 |
§3.4 Corolario
La idea central es que los contenedores aceptan [8] ciertos tipos de iteradores. Al mismo tiempo los algoritmos precisan también cierto tipo de iteradores como argumentos. La consecuencia es que los algoritmos pueden ser utilizados sobre aquellos contenedores que aceptan iteradores del mismo tipo. La idea se ilustra en la figura 2, donde se muestra como un Algoritmo A-1 puede utilizarse sobre tres contenedores distintos (C-1, C-2 y C-3) a condición de que estos acepten un iterador (I-1) compatible con el algoritmo. También puede presentarse la situación inversa, representada en la figura 3, donde se muestra como un contenedor C-1 puede ser manipulado por distintos algoritmos (A-1 y A-2), a condición también de que estos acepten un iterador compatible con el contenedor.
Otra consecuencia extraordinariamente importante, es que el diseño desligado de contenedores y algoritmos de la STL permite utilizar algoritmos definidos por el usuario sobre contenedores estándar (a condición de utilizar adecuadamente los iteradores aceptados por el contenedor). A la inversa, también es posible utilizar los algoritmos estándar sobre estructuras de datos definidas por el usuario a condición de que tales estructuras permitan a los punteros de sus miembros las propiedades que esperan encontrar los algoritmos en sus argumentos.
Observe que lo que proporciona a la STL su extraordinaria flexibilidad es el hecho de que en vez de diseñar los algoritmos para cada contenedor particular (como habría sido el caso de haberse aplicado los principios de la POO), se han diseñado para un iterador. A su vez cada contenedor está preparado para aceptar un tipo especial de iterador. Como resultado de este criterio de diseño se consigue cierta independencia entre algoritmos y contenedores, actuando los iteradores como nexo o vínculo de unión entre ambos.
§4 Espacio de nombres y ficheros asociados
Todas las entidades de la Librería Estándar C++ se han incluido en un único espacio de nombres
(![]() 4.1.11)
denominado std; de forma que para referirse a cualquiera de ellos
es preciso utilizar un designador cualificado del tipo:
4.1.11)
denominado std; de forma que para referirse a cualquiera de ellos
es preciso utilizar un designador cualificado del tipo:
std::vector;
std::vector<int> v(10);
En el apartado correspondiente hemos comentado los detalles
(![]() 4.11.c2
Acceso a miembros de la Librería Estándar). Además de esto, es
necesario incluir en nuestro programa el fichero de cabecera en que se
encuentran definidos los elementos de librería que pensamos utilizar.
En el caso anterior tendríamos que incluir la directiva:
4.11.c2
Acceso a miembros de la Librería Estándar). Además de esto, es
necesario incluir en nuestro programa el fichero de cabecera en que se
encuentran definidos los elementos de librería que pensamos utilizar.
En el caso anterior tendríamos que incluir la directiva:
#include <vector>
§5 Componentes
Los elementos de la librería STL se consideran divididos en cinco grandes categorías según su funcionalidad:
-
Contenedores: Estructuras de datos que albergan la información (
 5.1.1)
5.1.1) -
Iteradores: Nexo de unión entre los datos y los algoritmos; una generalización de los punteros (
5.1.2). -
Algoritmos: Conjuntos de operaciones estándar que se realizan sobre los datos de los contenedores. Adoptan la forma de funciones genéricas (
5.1.3). -
Objetos-función: Objetos que encapsulan una función. Son utilizados como argumentos de algoritmos (
5.1.3a1) para dar
flexibilidad a las operaciones definidas por estos, permitiendo que el usuario
especifique ciertos detalles (
5.1.3a). -
Asignadores (allocators
5.1.5) Encapsulan el modelo de memoria de la máquina. -
Adaptadores (adaptors
5.1.4) Se utilizan para proporcionar una
nueva interfaz a contenedores e iteradores, de forma que existen dos
tipos: adaptadores de contenedor y adaptadores de iterador.
§6 Bibliografía/Webografía
Existen muchos libros que describen la STL de C++ además de infinidad de artículos y resúmenes accesibles en la Web. Sin embargo, a mi entender el asunto es lo suficientemente importante como para merecer que se beba en las fuentes. En este, como en muchos otros casos, si se consulta la bibliografía de cualquier obra la materia, al final todas acaban en el mismo reducido círculo de autores, así que este es el mejor sitio donde dirigirse. Al fin y al cabo todos han (hemos) terminado bebiendo en la misma fuente. Siguiendo este criterio recomendaría dos obras fundamentales. La primer más didáctica. La segunda, más técnica, detalla los entresijos de la STL (no es desde luego un texto para introducirse en el tema, pero es "La Biblia" de la cuestión). Como siempre que se trata de textos informáticos recomiendo vivamente el original inglés (si el lector puede permitírselo).
"STL Tutorial and Reference Guide". Por David R. Musser; Guillmer J. Derge y Atul Saini (prologado por A. Stepanov) Addison-Wesley 2ª impresión Septiembre 2001. ISBN 0-201-37923-6
Nota: damos por supuesto que otra fuente de información importante es lo que el creador del lenguaje tiene que decir sobre el tema (aunque no sea el creador de la STL). Incluyendo los apéndices dedicados a localismos y al mecanismo de Excepciones en la STL, el Dr. Stroustrup dedica un 35 % de su TC++PL a la citada librería.
Respecto a los sitios Web, aconsejaría empezar por la página "C++ Reference"
de cplusplus.com
![]() www.cplusplus.com.
www.cplusplus.com.
Si necesita profundizar en los entresijos de la Librería y entender su
funcionamiento -no siempre fácil-, mi consejo sería visitar las páginas de ![]() Dr.Dobb's, y en el recadro de búsqueda,
introducir "Matthew H. Austern". Todos los artículos de este autor
que se refieren a la librería son interesantes y didácticos, además de
incluir observaciones y detalles que quizás no encontrará en ninguna otra
parte.
Dr.Dobb's, y en el recadro de búsqueda,
introducir "Matthew H. Austern". Todos los artículos de este autor
que se refieren a la librería son interesantes y didácticos, además de
incluir observaciones y detalles que quizás no encontrará en ninguna otra
parte.
[1] Podríamos establecer una analogía pensando en que una función puede actuar sobre un objeto que le ha sido pasado por referencia.
[2] Borland C++ Builder help; fichero BCB5.HLP
[4] Desde luego esto no es nuevo ni mucho menos. En la ciencia informática como en el resto, la comodidad tiene su precio. No solo los entornos de programación son más voluminosos cuanto más "inteligentes", también los programas de aplicación. Recuerden (los que puedan) la distancia entre un humilde WordStar para MS-DOS que cabía en un disquete de 360 KB y una moderna "suite" ofimática que consume 600 MB para... escribir una carta!.
[5] Al Stevens: "Entrevista a Alexander Stepanov" Dr. Dobbs's Journal. Marzo 1995. Un magnífico artículo que muestra en palabras de su creador la historia, evolución y principios que gobernaron el desarrollo y final aceptación de la STL como parte del Estándar.
[6] Alexander Stepanov "The Standar Template Library" Byte Magazine. Octubre 1995.
[7] Como consecuencia de ello, es recomendable un buen conocimiento del mecanismo de plantillas C++, antes de adentrarse en el estudio de la STL.
[8] Una explicación de como los contenedores pueden "producir" un
iterador (![]() 5.1.2a)
5.1.2a)